前言:为什么JavaScript SEO 越来越重要
JavaScript 在近几年来越来越兴盛,主要的原因在于JavaScript 能为网站带来许多不同的特效,也为访客体验增加不少了效果。
而在美国,也有多达80% 的电商网站使用JavaScript 生成主要的内容,或是产生产品对应的链接,JavaScript 对于网站的必要性也是越来越大,所以与其为了SEO 舍弃强大的JavaScript,不如让你的网站同时能拥有JavaScript 也能做好SEO。
就像Google 的John Mueller所说:
并不是说,SEOer 一定要学会JavaScript 这个程序语音,相反的,每位SEOer 都必须去了解Google 如何处理JavaScript 所产生的内容,并且适当的解决相关问题。
– John Muller
Google 的搜索引擎已经从早期的无法爬取JavaScript 内容,到现在能够渲染出JavaScript 的页面,Google 不断优化着自己的爬虫,但仍有许多的不足是我们需要留意的。而许多在做SEO 的营销人员也常常在问:『搜索引擎真的能够爬取JavaScript 吗?』
带着这个疑惑,本篇文章将从Google 爬虫原理出发,到如何建立友善爬虫的JavaScript 网页做详尽阐述。
从这篇文章中,你将会学到:
Google 搜索如何爬取网页内容
如何检查网站的JavaScript 问题
JavaScript SEO 的最佳做法
JavaScript SEO 常见问题有哪些
目录
1. JavaScript 是什么
2. Google 怎么爬取JS 网站
3. Google 爬取JavaScript 过程中重要节点
4. 如何打造JavaScript 友好的网站
5. 向Google 展示JavaScript 内容的不同方式
6. 如何建构一个友好SEO 的JavaScript 网站
一、JavaScript 是什么
讲到JavaScript 就要先讲到同为网页语言的HTML 跟CSS 语法,这三个语法分别为网页的呈现起到不同的作用:
HTML:网页的骨架,就像人体、又或是汽车,先有了骨架后,才可以开始长肉。
CSS:可以说是长在骨架上的肉,或是汽车上的颜色。
JavaScript:类似控制器,像是汽车的引擎、煞车、油门,替网站增加更多的运作与特效。
HTML 将网站的架构建好;CSS 为各个部分着色、提供不同的呈现;而JavaScript 替网页呈现出不同的特效,并依据不同的访客呈现不同的效果。于是乎此三种网页语言,让网页的呈现变的完整且方便有趣。

哪些内容可能是JavaScript 产生的呢?
1.主要内容
2.导航菜单
3.内部链接
4.商品评论
5.分类筛选器
所以,如果这些内容在JavaScript 上没有处理好的话,很容易造成索引及排名上遇到困难。
那如何检查网页上哪些内容是JavaScript 所产生的呢
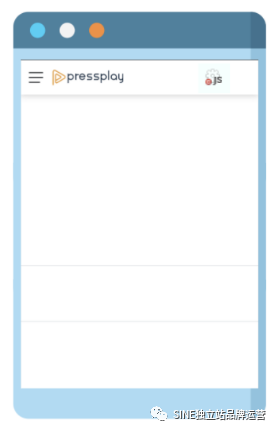
这边介绍的工具叫做『Quick Javascript Switcher』,这个插件可以直接开关网页的JavaScript 功能,只要你关掉JavaScript 后,发现哪个部分的内容不见了,那很大程度就是那个内容是JavaScript 所产生。
从下图可以看到,当我们用插件关掉JavaScript 功能后,Pressplay 的主要内容消失不见了,那就代表说其中主要内容由JavaScript 所产生。
首先点击鼠标右键找到『检查』,你会进入开发者介面。

接着使用快捷键『Control + Shift + p』 (Windows) 或是『Command + Option + p』 (Mac)。
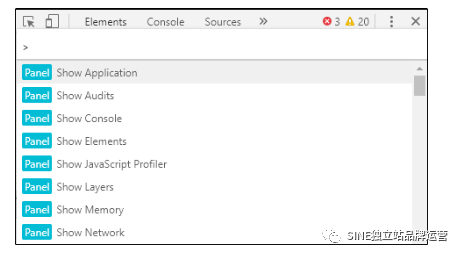
接着在光标处中输入JavaScript,就会看到一个『Disable JavaScript』选项,点击即可关闭JavaScript,同理要再打开只需使用相同方法再点击一次便可打开JavaScript 功能。
为什么网页源代码没有JavaScript 产生的内容!?
一般来说,我们在检查网页中的meta 标签、H 标签等内容时,最常做的就是从网页源代码中去查看,也就是『右键> 检查网页源代码』所呈现的内容。

而这个文件就是HTML 文件,但这份HTML 文件仅仅代表浏览器在解析页面时的最初讯息,而JavaScript 所产生的内容并不在一开始的HTML 文件上。
所以,检查网页源代码无法知道JavaScript 更新后的动态内容。
此时就要介绍一下HTML 加工后的DOM 了,这边为了不复杂化,简单叙述一下,当你『右键> 检查』出来的东西便是加工过的DOM(如下图)。DOM 里面会随着你与网站的互动,将JavaScript 所产生的内容加上去。
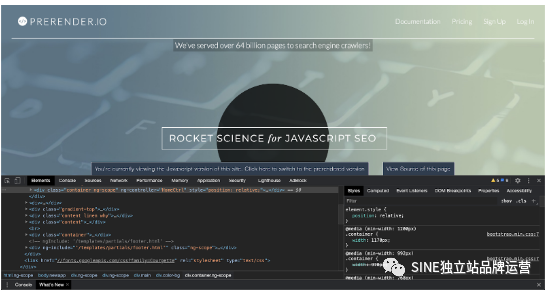
那如何区分HTML 源代码还是加工后的DOM 呢?


PS: 如果Google 爬取页面时无法完整呈现JavaScript 产生的页面,它至少可以索引为加载过的HTML 原始码。
在确认并且知道哪些内容属于JavaScript 所产生的之后,再就是理解Google 怎么爬取JavaScript,并且优化你的内容让网页排名上升。
二、Google 怎么爬取JS 网站
对于搜索引擎而言,JavaScript 一直是Google 努力在改善爬虫技术,让搜索引擎索引并排名的目标之一。虽然JavaScript 为访客带来更良好的使用体验,但是对于搜索引擎而言却不是一件容易的事情,请记得:

根据onely 网站调查指出,许多大品牌网页上JavaScript 之内容未被索引的情况:
Nike 网页上JavaScript 所产生的内容有22% 未被索引
H&M 网页上JavaScript 所产生的内容有65% 未被索引
Yoox 网页上JavaScript 所产生的内容有92% 未被索引
你可以想像,Yoox 在国外是知名电商网站,每个月可以有高达1400 万的流量,但是网站由JavaScript 产生的内容竟然由高达92% 是Google 不会索引到的,由此可知这样对SEO 的影响可以有多大,损失又可以有多多。
但同样的,也有把JavaScript 所产生的内容处理的很好的网站,allrecipes.com 以及boohoo.com 的网站分别让JavaScript 所产生的内容,被100% 及99% 的索引了,所以,只要方法得当,我们也能让JavaScript 与SEO 兼顾。
Google 爬取页面的过程
在早期搜索引擎只需要下载HTML 档便可完整了解网页内容,但由于JavaScript 技术的崛起及普及,搜索引擎甚至需要像浏览器一样,以便他们以访客的角度查看网页内容。
而Google 处理渲染的系统,被称为Web Rendering Service (WRS),中文可以翻译成网页渲染器,后面以WRS 代称,而Google 也给出了一张简化的图作为说明。

简单说明Google 爬取步骤,传统爬取HTML 档页面时,每项元素都很好爬取,整个索引并排名页面的过程也迅速:
1.Google bot 下载HTML 档
2.Google bot 从源代码中提取url 网址,并快速访问这些url
3.Google bot 下载CSS 档案
4.Google bot 将下载下来的资源送到Google 的Indexer
5.Google 的Indexer 检索页面
但如果是今天爬取JavaScript 所产生的网站内容的话,Google 会怎么爬取呢:
1.Google bot 下载HTML 档
2.Google bot 在源代码中找不到链接,因为JavaScript 未被执行
3.Google bot 下载CSS 及JavaScript 档案
4.Google bot 使用WRS(渲染器,Indexer 的一部分)解析、编译并执行JavaScript
5.WRS 从外部API、资料库获取资料(data)
6.Indexer 可以索引内容
7.Google 发现新的链接,并将其加入爬取排队队伍之中(Googlebot's crawling queue)。至此,执行一般Google bot 爬取HTML 页面的第二步。
可以发现,为了渲染出页面,Google 多了许多步骤。再来讲一下渲染过程中,Crawler、Processing、Renderer 及Index 之重要节点。
三、Google 爬取JavaScript 过程中的重要节点
Crawler(爬虫)
首先,crawler 会先向网站服务器发送一段请求(request),网站服务器会返回内容及其标头(header),然后crawler 将它储存起来。
而由于mobile-first indexing的关系,发送请求的可能大多都是来自手机版的爬虫(mobile user-agent),从Google Search Console上可以检查到,你可以透过网址审查或是涵盖范围来知道现在是电脑版索引还是手机版优先索引的状态。

然后有些网站会使用user-agent detection,侦测访客来到自己网站时,是用手机还是桌机、浏览器是什么、浏览器版本的不同资讯,再根据这些资讯给访客相对应的资讯,例如今天侦测到访客是用手机版本的chrome,便呈现手机版的页面给访客看。
需要注意的是,有些网站遇到爬虫时可能会设定禁止该爬虫爬取页面,或是禁止特定地区ip 的访客查看页面,这时候就要小心如果网页没设定好的话,很有可能爬虫是看不到你的内容的喔。
记得从几个方面测试看看Google 爬虫能否顺利看到你的页面:Google Search Console 的网址检查器、移动友好测试工具以及富媒体结果测试工具。
补充:从爬取过程那张图可以看到,Google 将爬取后产生的页面称之为HTML,但实际上,为了建构页面内容,Google 其实爬取并储存了相关所需的资源,像是CSS 文档、JS 文档、API 端口、XHR requests等相关资源。
Processing(处理)
Processing 的过程中其实是非常复杂且处理很多事的,这边重点讲述Google 处理JavaScript 的过程。
(一)遵循限制性最高的要求
什么是限制性最高的要求,就是假设今天Google 渲染(render)出页面后,原本meta robots 的信息是index 被加入了noindex,那么Google 将不会索引其页面,甚至其它尚未被渲染的页面,因为JS 产生noindex 这类的语法,则可能导致页面无法被渲染。
(二)处理资源及链接
Google 并不像访客那样浏览页面,Processing 的过程中有个很重要的工作便是检查页面上的链接以及建构该页面所需的文档。
这些链接被记录,加到等待爬取的排队序列中(crawl queue),反覆执行找链接、链接排队、爬取链接,便是Google 本身爬取整个网路世界的方式。
Google 透过属性,将建构页面所需的资源,像是JS、CSS 文档被记录。但是页面对页面的链接需要以特定的形式所呈现,才能被Google 所抓取,那就是以链接”>的形式。
<a href="/good-link">能被爬取的連結a>
<span onclick="changePage('bad-link')">不能被爬取的連結span>
<a onclick="changePage('bad-link')" >不能被爬取的連結a>
<a href="/good-1ink" onclick-"changepage('good-link')">能被爬取的連結a>
如果你的链接是JavaScript 所产生的话,那必须等到页面被渲染后,爬虫才能爬到。但有个风险就是,不一定页面上的内容全数都能被成功渲染,有可能因为检索预算不足的情况下渲染不到你的链接,所以务必留意链接的部分。
(三)删除重复内容
Google 倾向将重复页面删除,或者是降低重复页面的爬取优先级别。许多JavaScript 所产生的网页,都会有个app shell models,可以想像他是最小化的HTML、CSS 及JS 所组成,用户可以在不同需求下再次载入所需要的内容。
但这有一个问题就是,app shell models 只有最简单少量的内容及源代码,所以很有可能被Google 误判为重复性内容,也造成其页面能够被渲染的优先级下降,正确的内容无法被索引,以及错误的页面被排名。
(四)缓存及其它
Google 下载页面HTML、CSS、JS 文档并渲染后,就会将其缓存。并且还有其它许多事情是Google 会同时处理的,并不止于这些,但处理页面的部分重点就在上述几项。
Render queue (渲染序列)
接下来许多页面即将被渲染, 所以在渲染排队中,根据Google 早期的说法,由于检索预算的优化,渲染页面并检索会是比较后期的事,俗称第二波索引( two waves of indexing ),但其实在近期onely 的Bartosz Goralewicz 与John 及Martin 讲述到,第二波索引的影响其实越来越小,Google 在等待渲染的中位数时间也只有5 秒钟,可见Google 在渲染并索引这一块下了相当大的功夫,未来渲染也将与检索能够同步进行。
Renderer(渲染器)
还记得前面说的食谱与料理吗?页面在渲染前的DOM 跟渲染后的DOM 就像料理的食谱,以及做好的烤鸡一样,简单讲DOM 就是像图中那树状图所呈现。

料理前的食谱是不会改变的,所以渲染前的页面源代码一样不会因触发JavaScript 而改变,所以可以想像Renderer 就是一个主厨,料理食谱并且产生一道料理(JavaScript 渲染出来的页面),Renderer 为的就是去渲染出JavaScript 相关内容。
要知道光是可以爬取整个网路世界成千上亿的资料便是不容易,还要将其内容渲染出来耗费资源非同小可,根据onely 指出,为了让JavaScript 内容被爬取、渲染并且索引,耗费的资源是一般HTML 页面的20 倍,一定要格外小心。让我们看看渲染器中有哪些重要的东西吧。

(1)快取资源(Cache Resource)
Google 相当重度依赖快取,它会快取各种文档,文档快取、页面快取、API requests 等,在被送到渲染器前就会先快取起来。因为不太可能每准备渲染一页,Google 就下载一次资源,所以优先快取好的文档资源就能快速渲染页面。
但这也带来几个问题,有可能Google 会快取到旧的档案、旧版本的资源,导致在渲染页面时出现错误。如果有这种状况出现记得做好版本控制或是内容指纹,让Google 可以知道你更新了新的内容。
(2)没有特定逾时时间(No Fixed Timeout)
很多网上谣传渲染器只会用5 秒渲染你的页面,但其实并不然,Google 渲染时可能会加载原有快取的档案,会有5 秒的这一说法,主要是因为网址审查工具相关工具,检测页面时需要获取资源所以需要设立合理的逾时时间。
为了确保内容完整呈现,Google 没有特地设定逾时时间,但为了爬虫爬取及访客体验,更快的速度一定是更好的。
(3)渲染后,Google 看到了什么?
这边要提到一个很重要的点是,Google 并不会主动与网页上的内容做互动,所以有些JavaScript 的特效,需要访客点击或触发的特效,是不会被Google 所触发,不会点击更不会滚动页面。
所以早期你们一定有听过一个说法,不要使用瀑布流网页的原因就是如此,因为Google 不会卷动你页面的情况下,就无法触发JavaScript 所产生的内容,但Google 也不笨喔,为了克服瀑布流,他们直接把机器人设定成一台超长版手机,这样可以直接渲染出指定长度的内容。
可是一般需要JavaScript 触发的内容无法被Google 渲染出来了喔,所以一定要特别注意,链接也不要出现JavaScript 所产生之链接。

四、如何打造JavaScript 友善的网站
前面我们说到JavaScript 现在越来越重要,也是越来越多网站使用的技术,所以与其完全避开使用JavaScript,不如打造一个既能满足开发者需求,又能争取排名的JavaScript 网站,让来看看有哪些重要因素吧。
1.可被爬取(Crawlability):确保你的网站能保持良好的结构被爬取,并且爬虫也能找到有价值的内容。
2.可被渲染(Renderability):确保页面上的内容可以被渲染。
3.爬取预算(Crawl budget):Google 花了多少资源及时间渲染你的页面
你的JavaScript 内容对搜索引擎足够友善吗?
首先检查。你要知道你的网页在Google 眼中长的如何,那到底有哪些常见检查方法,这些方法正确吗?
1.透过网址审查工具
Google Search Console 的网站审查工具可以呈现渲染后的页面,其它官方的工具包含AMP 测试工具、富媒体搜索结果测试等官方检测工具,皆能呈现出渲染后的样貌,这边以移动友好测试工具为例。
可以看到屏幕截图的画面,显示出Google 渲染出的画面,可以试着去看屏幕截图,重要内容是否能够被渲染出来。
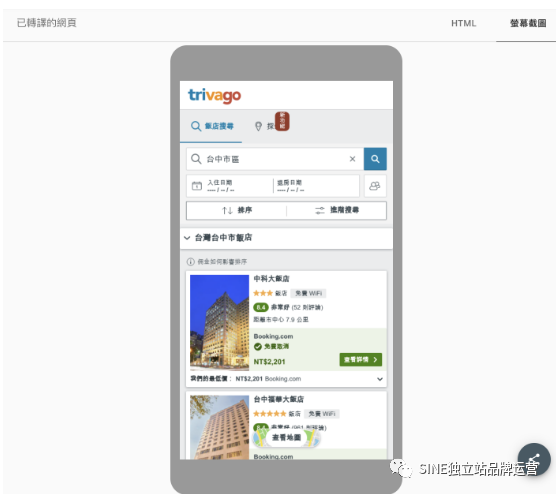
渲染后的屏幕画面
另一方,你可以从检查工具的源代码中查看内容是否有被渲染出来,直接搜索内容、H 标签等方式确认。
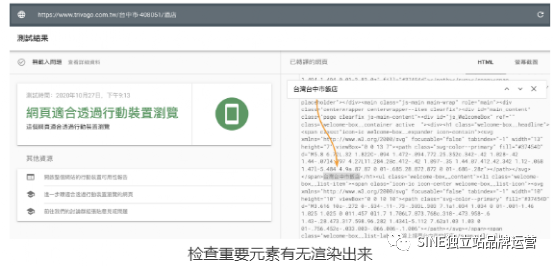
记得从渲染后的HTML(DOM – the rendered code)检查:
主要内容是否可以呈现
推荐文章或推荐商品可以渲染出来吗
Google 还有没有办法看到其它重要元素
2.site 指令+关键字检查
site 指令一般而言,大多用来检查页面在Google 之收录状况,那如果说你直接『site:网址』后发现页面有被Google 收录,你就能用这个方法检查,因为Google 其实会根据关键字修改搜索结果页上的Description,所以当你输入一段内文时,Google 其实很有可能根据你这一段内文呈现在Description 上给你看。
以pressplay 页面为例,pressplay 上的课程简介其实就是用JavaScript 去产生的,下图中可以看到,当我们将JavaScript 功能关闭时,就会发现内容只剩下下面那一段,那么要确认Google 是否有索引到主要内容便可用『site 指令+关键字』做检查。

只有上面红框文字非JavaScript 产生。
而在连老师『每月给你SEO最新趋势』这堂课中会发现,只要将JavaScript 功能关掉,主要内容便只剩下其中红框这一段,再来,复制一段JavaScript 产生内容的文字『每年服务客户横跨12大产业,我们了解你的产业问题,资深SEO专家团队陪你洞悉新·SEO』+ site:网址试试看。
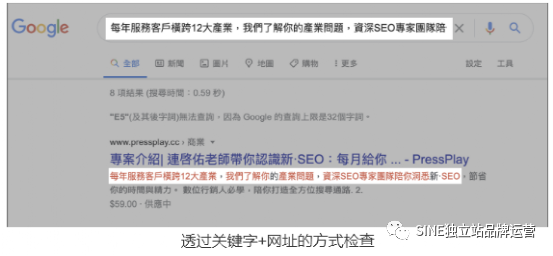
有没有发现,其实JavaScript 产生的内容Google 是有渲染出来并且索引到的,但如果要更准确的检查,建议还是要从官方的网址测试工具查看。
注:网址审查工具:
Google Search Console 网址审查工具https://www.seo-tea.com/google-search-console-tutorial/#%E7%B6%B2%E5%9D%80%E5%AF%A9%E6%9F%A5
结构化测试工具https://search.google.com/structured-data/testing-tool/u/0/?hl=zh-TW
富媒体搜索结果测试工具https://search.google.com/test/rich-results
AMP 测试工具https://search.google.com/test/amp?hl=zh-TW
移动友好检测工具https://search.google.com/test/mobile-friendly
Google 无法索引我的网页怎么办
刚刚前面有提到,透过网址审查工具首先检查Google 渲染页面的状态为何,如果渲染未出现主要内容,那么就可能导致内容无法被索引,你需要透过网址审查工具中的更多信息,查看是否有资源遭到阻挡。
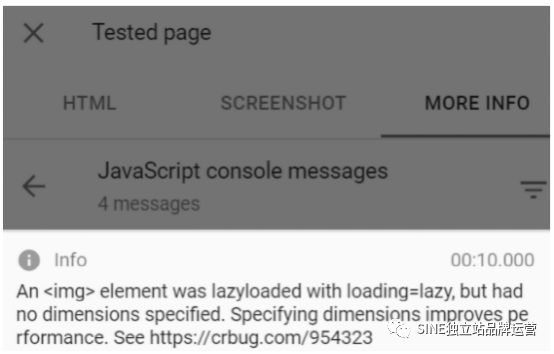
更多信息中会告诉你哪些资源遭到封锁
所以,先确保内容是否能被正确渲染后,再确保能否被索引,接着才能优化内容竞争排名。
Google 未能索引你网页的原因:
渲染时逾时:是否载入时耗费资源过大,导致访客及Google 都无法渲染页面
是否资源遭到阻挡:检查Robot.txt 文件,确认Google 是否渲染时资源遭受阻挡
Google 渲染时遇到问题:透过网址审查工具检查页面详细状况
重复页面问题:是否有其它重复页面导致内容无法被索引
Google 无法发现该页面:没有内部链接,或是Sitemap.xml 无该页面导致Google 无法发现
其它……
了解Google是否能渲染你的内容,是否能正确索引,然后再争取排名,一步步找出问题并解决它。
五、渲染方式的不同:向Google 展示JavaScript 内容的不同方式
你以为你的页面对Google 来说只是渲染出来,然后查看内容、收录并且排名吗?其实没那么简单,网页渲染的呈现方式还能分为客户端渲染(Client Side Rendering)、服务器端渲染(Server Side Rendering)、混合式渲染等方式。
SSR(服务器端渲染),通常对于Google bot 以及访客而言,能够接受到完整的HTML 档案,内容也已经呈现好了。
CSR(客户端渲染),近几年来越来越流行的渲染方式,对于Google bot 及访客而言,最初拿到的页面几乎是空白的HTML 档案,随着访客的操作,JavaScript 非同步的产生并下载内容。用料理与食谱来比喻,Google bot 及访客都只拿到了一份食谱,后面呈现端看访客如何烘培蛋糕(操作网站)。
但是,Google bot 并不像访客一样,会有许多花里胡哨的操作,Google bot 不会滚动、不会点击更不会跟网站进行互动,所以如果你是全CSR(客户端渲染)的页面一定要注意,解决方法如下:
① 服务器端渲染(SSR)
敞偌你的页面因为JavaScript 渲染问题导致页面无法被索引,那强烈建议将重要页面或是网站改成服务器端渲染。
② 动态渲染(Dynamic Rendering )
有时候当然不可能说全改成SSR ,于是动态渲染就变成当今蛮重要的一种渲染方式,能同时做到CSR 想呈现的效果,又能同时达到SEO 排名。
从下图可以看到,网页使用了全JavaScript 所产生的内容,但是提供给Google bot 的是另一静态HTML 页面,很好的解决了Google 爬虫无法查看渲染页面的问题。
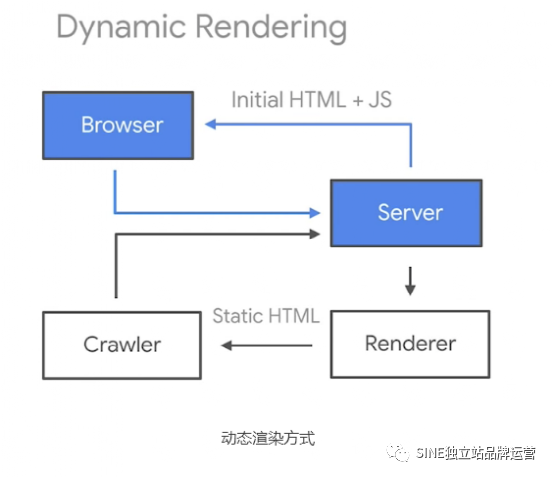
以下三种服务可以很好的帮助你实现动态渲染功能:
Prerender.io https://prerender.io/
Puppeteer https://developers.google.com/web/tools/puppeteer
Rendertron https://codelabs.developers.google.com/codelabs/dynamic-rendering?hl=zh-tw#0
Google 官方文件也提供了转译原理、说明及方式,推荐大家看看。而下图是各种渲染JavaScript 的方法,其实大部分对于Google 来说都是渲染的出来的,比较难的还是在CSR(客户端渲染)的部分,所以如果你是CSR 建议导入动态渲染喔。
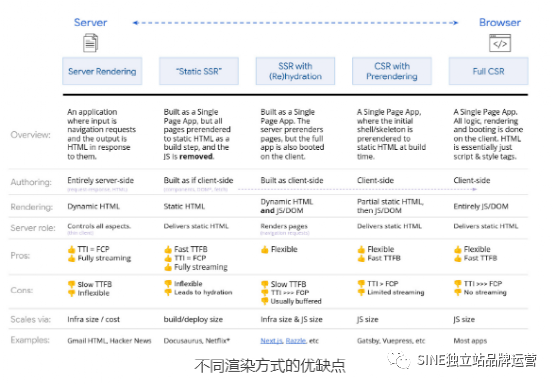
六、如何建构一个友善SEO 的JavaScript 网站
其实这个小节的内容有部分你可能过去就知道了,但因为JavaScript 的关系仍有部分不同。
允许Google 爬取
如果连网页都不能爬取、渲染的JavaScript 资源都无法读取的话,就不用说要排名啰,记得Robots.txt里不要禁止渲染相关资源,在Robots.txt中加入以下指令:
User-Agent: Googlebot
Allow: .js
Allow: .css
On-page 优化
基本上on-page 上的重要元素应该都要能够被呈现出来,记得透过网址审查工具仔细检查是否都有出现:
Title/Description
H 标签
主要内容
meta robots 标签
alt 标签
JavaScript 网站最常出现的一个状况是重复Title/Description 被重复使用,记得可以从Google Search Console 中的涵盖范围查看,又或者透过Screaming Frog 等工具确认。
网址的点击
前面虽然都有提到,但这边还是正式说明一下,在2018 年的Google I/O 大会上便说到,因为Googlebot 并不会去点击、滚动或是与网页做互动,所以如果你的链接是以onclick 的方式呈现的话,将不会被Googlebot 所爬取。
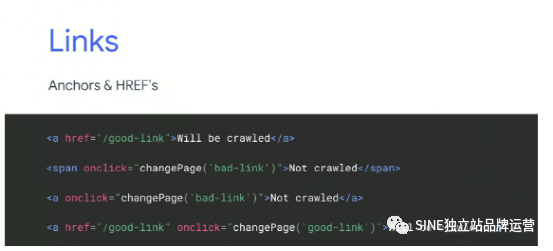 对Google 而言,好链接与坏链接
对Google 而言,好链接与坏链接
同样的,在导航上、分页上、内容上一样切记要使用 的方式去呈现链接,才能确保Google 会发现并爬取你的链接。
网址的更新
对于部分网页采用SPA(Single Page Application)方式所呈现的网页,在更新网页时,必须使用History API,对于较早期的开发者而言,在更新网页Url 时采用的是片段(fragement)的方式,那网址就会变成我们常见的锚点,如下:
Our products
但以『#』这种形式的连结对于Google 来说并不会抓取喔!虽然早期开发出一种连结形式,将『#』取代成『#!』,但这种方式已经过时了,网址也会变得相当丑。
但是透过History API 的方式就能让网页资讯变动时,链接才会变换成Google 可爬取的形式,完整介绍可参考Google 官方文件。
错误页面
因为JavaScript 框架是客户端而非伺服务器端,所以像是当SPA 页面产生错误时,并没有办法传递出404 状态码到服务器中,此时请采取以下其中一种方式解决:
l使用JavaScript 转移到你原本就设定好404 状态码及页面不存在讯息之页面
l将错误页面加上noindex 标签,并在页面上呈现『404 页面错误』信息,这样子页面就能被视作软404(soft 404)的状态。
Sitemap
我们可能因为使用JavaScript 产生了网站的许多内容,并没有办法说一次到位,解决所有JavaScript 产生的SEO 问题,此时Sitemap.xml 有着重要的角色,就是告知Google 网站重要的页面有哪些,对于你提交的页面,Google 可能会优先爬取。
但同时,你也必须确保Sitemap 上的所有页面链接没有以下问题:
重复内容
被canonical 指到别的页面
404 错误页面
301 转址到其它页面
空白页面
等等…
这样Sitemap 才能真正的发挥他的作用,让Google 知道你重要的页面。
总结
JavaScript 所产生的内容,已经不像过往几年Google 爬虫完全无法理解,随着开发技术的进步JavaScript 也成为网页开发的重要元素,所以不要急着排斥它。
记得首先,让Google 能够渲染出你的页面;其次,确认Google 有顺利索引你的页面;接着,按着你一般优化SEO 的方式,排除重复内容、优化内容,加强关键字排名。
这看似简单的几个步骤就花了很大一个篇幅在说明了,所以一起努力建立一个友善SEO 的JavaScript 网站吧!
参考资料:
l了解JavaScript 搜寻引擎最佳化(SEO) 基础知识 https://developers.google.com/search/docs/guides/javascript-seo-basics
l修正会影响搜寻体验的JavaScript 问题 https://developers.google.com/search/docs/guides/fix-search-javascript
l导入动态转译 https://developers.google.com/search/docs/guides/dynamic-rendering
lRendering on the Web https://developers.google.com/web/updates/2019/02/rendering-on-the-web
lJavaScript SEO: What You Need to Know https://ahrefs.com/blog/javascript-seo/
lThe Ultimate Guide to JavaScript SEO (2020 Edition) https://www.onely.com/blog/ultimate-guide-javascript-seo
lJavaScript and SEO: The Difference Between Crawling and Indexing https://www.stateofdigital.com/javascript-seo-crawling-indexing/
lMaking JavaScript and Google Search work together https://web.dev/javascript-and-google-search-io-2019/
lRendering SEO manifesto – why JavaScript SEO is not enough https://www.onely.com/blog/rendering-seo-manifesto/
lJavaScript vs. Crawl Budget: Ready Player One https://www.onely.com/blog/javascript-vs-crawl-budget-ready-player-one/
lEverything You Know About JavaScript Indexing is Wrong https://www.onely.com/blog/everything-you-know-about-javascript-indexing-is-wrong/
lStatic vs. Server Rendering https://frontarm.com/james-k-nelson/static-vs-server-rendering/
lDeliver search-friendly JavaScript-powered websites (Google I/O '18) https://youtu.be/PFwUbgvpdaQ
lJavaScript SEO – How Does Google Crawl JavaScript https://seopressor.com/blog/javascript-seo-how-does-google-crawl-javascript/
翻译作品, 原作者:分解茶
文章为作者独立观点,不代表DLZ123立场。如有侵权,请联系我们。( 版权为作者所有,如需转载,请联系作者 )

网站运营至今,离不开小伙伴们的支持。 为了给小伙伴们提供一个互相交流的平台和资源的对接,特地开通了独立站交流群。
群里有不少运营大神,不时会分享一些运营技巧,更有一些资源收藏爱好者不时分享一些优质的学习资料。
现在可以扫码进群,备注【加群】。 ( 群完全免费,不广告不卖课!)






发表评论 取消回复