
当尖叫与奸笑撕破女厕所的平静 —— 是标识牌误导让老实人误入歧途?还是法外狂徒硬闯?
你的独立站 robots.txt 正面临和 【厕所指示牌】同样困境:爬虫大军中混杂着迷路的「误闯者」也有蓄谋已久的「偷窥狂」。
怎么修改网站的 robots.xtx 文档
分2部分 Shopify 与 WordPress(Yoast)的路径指南
1. Shopify 平台的 robots.txt 修改流程
Shopify 为商家提供了编辑 robots.txt 文件的功能,以此对搜索引擎爬虫的抓取范围进行自主调控,具体操作步骤如下:
-
登录 Shopify 管理后台
使用商家账号登录 Shopify 店铺的管理页面。 -
进入主题编辑界面
点击页面中的 “在线商店” 选项,随后选择 “主题”。在主题页面中,找到正在使用的 “实时主题” 板块,点击其旁边的 “操作” 按钮,并选择 “编辑代码”。 -
创建 robots.txt 模板
在代码编辑界面左侧的文件目录中,找到 “模板” 部分,点击 “添加新模板”。此时会弹出一个选项框,将 “创建新模板用于” 的选项更改为 “robots.txt”,最后点击 “创建模板”。Shopify 会自动生成一个名为 “robots.txt.liquid” 的文件,这个文件包含了店铺默认的 robots.txt 规则。 -
编辑 robots.txt 内容
在生成的 “robots.txt.liquid” 文件中,你可以根据实际需求修改规则。比如,若要阻止特定搜索引擎爬虫访问某个目录,可以添加类似 “Disallow: / 特定目录名 /” 的指令;若要添加网站地图链接,可使用 “Sitemap: https:// 你的域名 /sitemap.xml” 的格式进行添加。完成修改后,点击保存,新的规则便会生效。
2. 借助 Yoast 插件修改 WordPress 的 robots.txt
Yoast SEO 插件是 WordPress 生态中一款强大的 SEO 优化工具,利用它可以便捷地对 robots.txt 文件进行修改:
-
安装并激活 Yoast SEO 插件
登录 WordPress 网站的后台管理界面,点击 “插件” 菜单,选择 “添加新插件”。在搜索框中输入 “Yoast SEO”,找到该插件后点击 “安装” 按钮,安装完成后再点击 “激活”。 -
进入文件编辑器
在 WordPress 后台左侧菜单中点击 “Yoast SEO”,在展开的选项中选择 “工具”,然后点击 “文件编辑器”。若 WordPress 禁用了文件编辑功能,该菜单选项可能不会出现,此时需要先在服务器层面或通过主机提供商开启文件编辑权限。 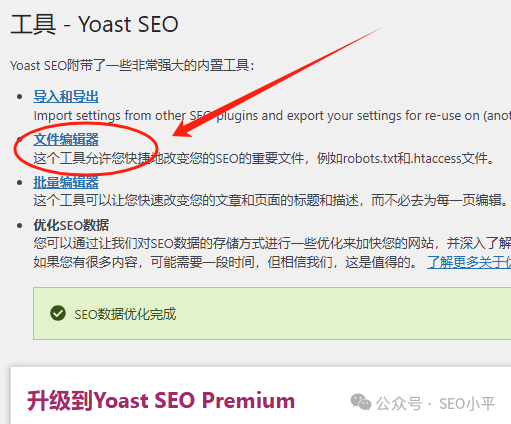
-
编辑 robots.txt
点击 “创建 robots.txt 文件” 按钮(若已存在该文件,则直接显示文件内容),Yoast SEO 会展示生成的默认 robots.txt 内容。在这里,你可以对文件进行编辑操作,例如添加或删除特定的 “Disallow”“Allow” 指令等。修改完成后,点击保存即可。
一、基础规范:从命名到缓存的底层逻辑
1. 命名与位置:爬虫识别的 “门槛”
-
命名规则
文件名必须严格为小写的 robots.txt,大小写错误(如Robots.TXT)会导致爬虫直接忽略文件内容,进而引发抓取失控。 -
存储位置
文件需放置在网站根目录(如 https://example.com/robots.txt),子目录存储(如/pages/robots.txt)无效。此外,不同协议(HTTP/HTTPS)、主机名或子域名(如shop.example.com)需单独配置独立的 robots.txt 文件,避免规则冲突。
2. 路径与指令的大小写敏感机制
-
路径匹配
Disallow和Allow指令中的 URL 路径区分大小写(如/folder/与/Folder/视为不同规则),错误的大小写会导致规则失效。 -
爬虫名称匹配
谷歌对 User-agent值(如Googlebot)不区分大小写,但其他搜索引擎可能敏感,建议统一使用小写规范。
3. 缓存机制:修改生效的 “时间差”
-
谷歌通常缓存 robots.txt 内容长达 24 小时,若遇服务器错误(如 5xx 状态码),缓存时间可能更长。 -
可通过 Cache-Control响应头的max-age指令调整缓存周期,或借助 Google Search Console(GSC)请求加速刷新。
二、核心指令:精准控制抓取行为的 “工具箱”
1. User-agent:定位目标爬虫
-
通配符规则
User-agent: *匹配所有遵守协议的爬虫,规则优先级低于具体爬虫声明(如Googlebot)。 -
各种爬虫细分
针对不同功能的谷歌爬虫(如 Googlebot-Image负责图片抓取),可单独配置规则,实现精细化控制。
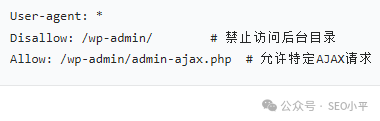
2. Disallow 与 Allow:禁止与放行的博弈
-
禁止抓取
Disallow: /可阻止指定爬虫访问全站;路径支持文件(如/private.html)、目录(如/admin/)或通配符模式(如/*?sessionid=*禁止含会话 ID 的 URL)。 -
精准放行
-
路径长度优先
当同一 URL 匹配多条规则时,路径前缀最长的规则生效。例如: Allow: /folder/page(长度 12)优于Disallow: /folder/(长度 8)。 -
冲突处理
若路径长度相同(如 Allow: /page与Disallow: /page),谷歌遵循 “限制性最小” 原则,优先执行Allow。
4. 通配符高级应用:* 与 $ 的组合艺术
-
*匹配任意字符可用于禁止含特定参数的 URL(如 /*?color=阻止含颜色过滤参数的页面)或文件类型(如/*.pdf禁止所有 PDF 文件)。 -
$匹配路径结尾精准区分目录与文件(如 Allow: /search/$仅允许根目录的search页面,排除/search/results.html)。
三、策略对比:robots.txt 与其他 SEO 工具的协同
robots.txt Disallow |
robots.txt 文件 |
||||
noindex |
<head> 部分 |
||||
X-Robots-Tag: noindex |
|||||
rel="canonical" |
<head> 部分或HTTP响应头 |
1. 与 noindex 的分工
注意:若页面在 robots.txt 中被Disallow,谷歌将无法读取其noindex标签,导致索引控制失效。
2. 与 Canonical 标签的互补
-
rel="canonical"用于整合重复内容的权重,需确保非规范页面可被抓取(即不被 robots.txt 阻止),否则标签无效。 -
策略选择
参数化 URL 若需保留链接信号,优先使用 canonical;若需彻底阻止抓取,再用Disallow。
四、实战场景:从参数处理到资源优化
1. 参数化 URL 管理
-
会话 ID 与跟踪参数
通过 Disallow: /*?sessionid=或/*?utm_source=阻止无价值参数页面。 -
分面导航
结合通配符(如 /*?*color=)与canonical标签,保留核心过滤组合页面,屏蔽冗余参数组合。
2. 分页内容处理
-
推荐策略
索引第一页,后续页面使用 noindex, follow,允许抓取以传递链接权重。 -
避免误区
禁止通过 robots.txt阻止分页 URL,否则会阻断深层内容的发现路径。
3. 资源文件抓取策略
-
核心原则
允许抓取 CSS、JS 等渲染必需资源,避免谷歌无法正确解析页面内容。 -
例外情况
仅当资源为装饰性或非必要(如第三方跟踪脚本)时,可谨慎阻止。
在更广阔的SEO图景中的定位
robots.txt 禁止抓取某个URL,并不能保证该URL不会被索引如果谷歌通过其他途径(如外部链接、内部链接或站点地图)发现了这个被禁止抓取的URL,它仍然可能将该URL编入索引。正如女厕所有一个侧门,有一些男人从侧门进入了女厕所。这种情况下,由于谷歌未能抓取页面内容,搜索结果中通常不会显示该页面的描述,有时可能会显示URL本身或指向该页面的链接锚文本
我是9年独立站卖家SEO小平,一直分享谷歌SEO的干货,更多关于外包SEO的详细干货我会在我们的陪跑课程里面系统分享。欢迎报名我们的下次陪跑课程。先加我的微信 Xiao_Ping_Up ,或者扫描二维码
以往的文章也是干货,欢迎阅读和转发
谷歌算法又双叒叕更新?Google SEO算法为啥一直在更新?
文章为作者独立观点,不代表DLZ123立场。如有侵权,请联系我们。( 版权为作者所有,如需转载,请联系作者 )

网站运营至今,离不开小伙伴们的支持。 为了给小伙伴们提供一个互相交流的平台和资源的对接,特地开通了独立站交流群。
群里有不少运营大神,不时会分享一些运营技巧,更有一些资源收藏爱好者不时分享一些优质的学习资料。
现在可以扫码进群,备注【加群】。 ( 群完全免费,不广告不卖课!)







发表评论 取消回复