
llms.txt 标准的提出旨在解决一个根本性挑战:大型语言模型(LLM)难以高效地解析标准网页,这些网页通常充斥着与核心内容无关的 HTML、JavaScript、CSS 和广告
为应对此问题,Answer.AI 的 Jeremy Howard 于 2024 年 9 月首次提出了一项解决方案:引入一个简单、结构化的纯文本 Markdown 文件(/llms.txt),作为 AI 的“备忘单”或“发现指南”
主要 AI 开发商的官方对 llms 的评价
-
谷歌 (Gemini):谷歌的 John Mueller 态度明确。他在 Bluesky 上表示:“仅供参考,目前没有任何 AI 系统使用 llms.txt”
它们中没有一个会去抓取 llms.txt 文件 ”keywords 元标签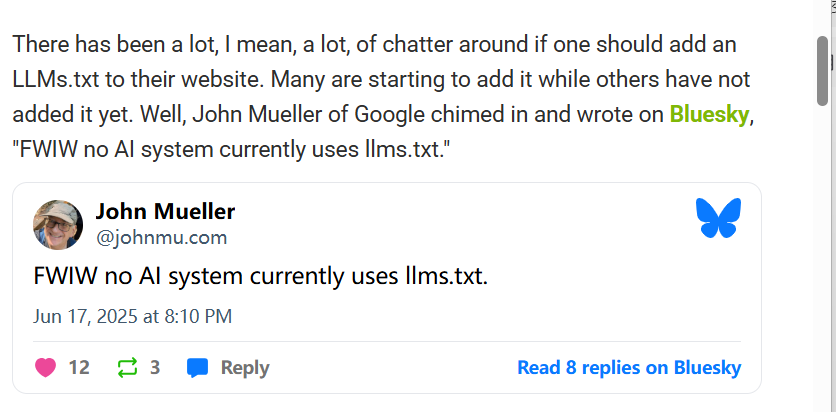
-
OpenAI (ChatGPT):OpenAI 为其爬虫(如
GPTBot、ChatGPT-User)发布的官方文档中并未提及llms.txt。ChatGPT官方文档只详细地说明了如何使用robots.txt来授予或拒绝访问 Anthropic (Claude):同样,Anthropic 为其爬虫(如
ClaudeBot、Claude-User)发布的文档也详细说明了通过robots.txt进行控制,甚至提到了非标准的Crawl-delay指令,但完全没有提到llms.txt使用 了llms.txt文件
llms.txt 不是AI的灵丹妙药,核心还是要关注内容本身的质量
-
专注于内容质量和结构。为人类编写清晰、组织良好的内容。使用正确的 HTML 标题(H1, H2 等)、列表和结构化数据(Schema.org)。这使得内容对人类和 AI 都更容易解析,是比依赖一个单独文件远为有效的策略
-
llms.txt照样添加上,但不要花太多精力既然Yoast能轻松搞定,那肯定还是把他添加上,总之没有坏处,有没有AI流量的好处,还不知道。 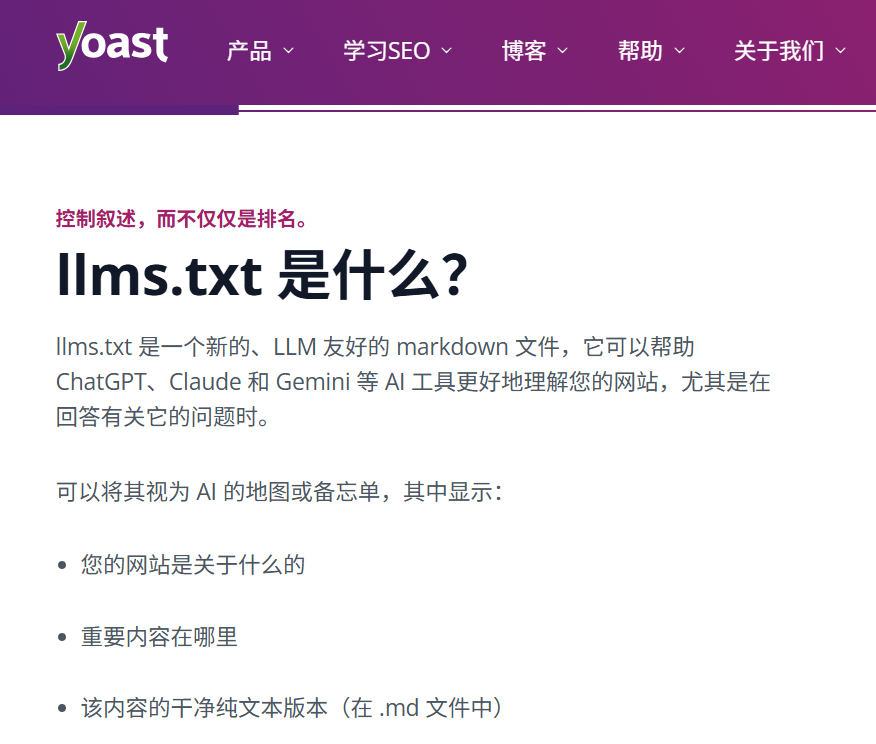
以往的文章也是干货,欢迎阅读和转发
谷歌算法又双叒叕更新?Google SEO算法为啥一直在更新?
文章为作者独立观点,不代表DLZ123立场。如有侵权,请联系我们。( 版权为作者所有,如需转载,请联系作者 )

网站运营至今,离不开小伙伴们的支持。 为了给小伙伴们提供一个互相交流的平台和资源的对接,特地开通了独立站交流群。
群里有不少运营大神,不时会分享一些运营技巧,更有一些资源收藏爱好者不时分享一些优质的学习资料。
现在可以扫码进群,备注【加群】。 ( 群完全免费,不广告不卖课!)



![[快讯]Google发布2026年5月核心算法更新](https://cdn.dlz123.cn/uploads/images/2026-05-24/sz_mmbiz_jpg/UrQ0u8YMicLfwmEDPoTYAeHkU9nZE2pLjibgvcjRgOeZaZcy8rQsff0wJwfSCiaTwW1ZfzecWPdQXS1yOlLAbqySGEibc1VxOq6bOZAtrHOrzDs.jpeg&from=appmsg?imageMogr2/thumbnail/!30p)



发表评论 取消回复