本篇笔记不是新闻视角,而是新闻背后的 HOW TO DO STEP BY STEP.
额,为什么单独把Robots.txt协议拿出来研究?Shopify CEO Tobias Lütke上个月19号发了个推,如下图:
对了,Tobias Lütke 刚刚入选了《2021年最佳CEO榜单,巴伦周刊》
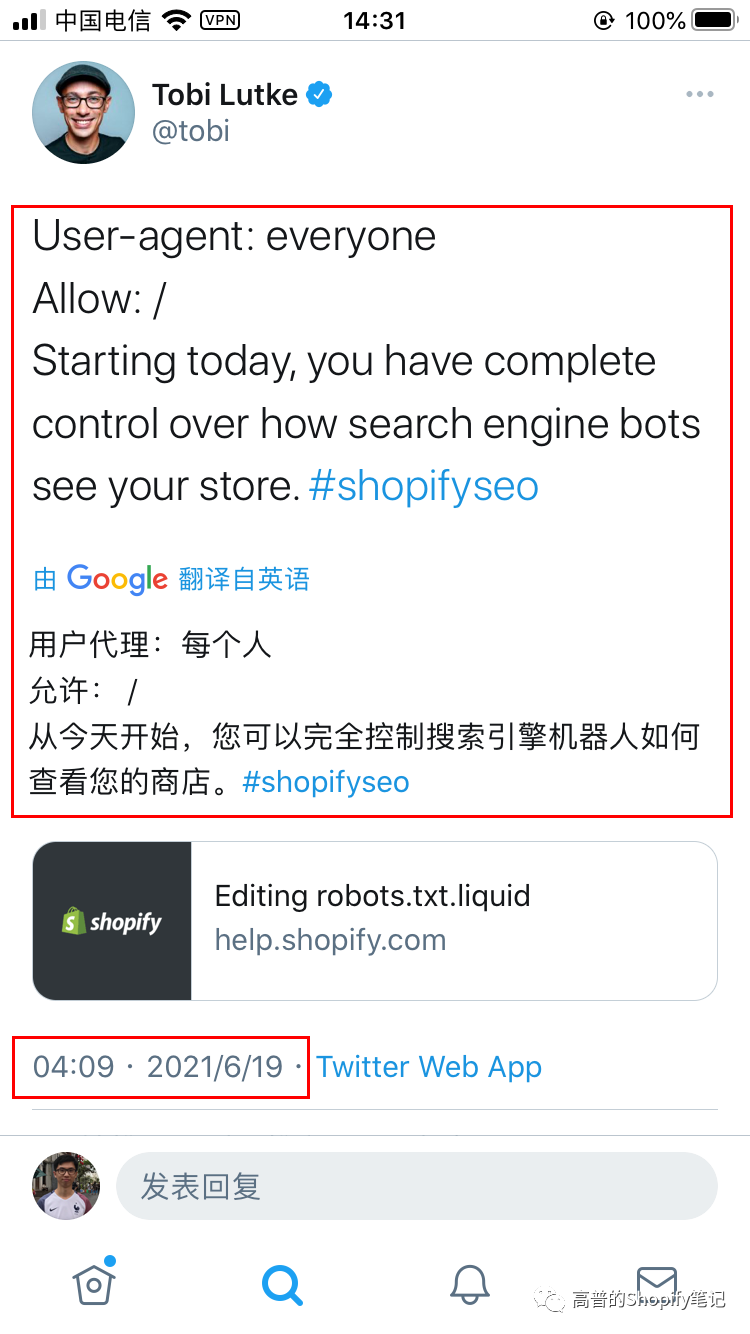
当时,我看到这个推的时候,也是一脸懵逼?到底怎么编辑?为什么要编辑?不编辑可不可以?SEO小bai满脸的问号。
额,下面的篇幅,则是看起来好像没啥直接用处的,可能会有些枯燥的技术知识点。对于,越是模棱两可的知识点,我越是有颗好奇心探究,所有看似零碎无序的线索,最后汇聚到一起融会贯通的时候,我相信,绝对不是巧合!万丈高楼平地起,辉煌只能靠自己(这歌谁唱的。。。真的好土)?
本篇笔记,本来应该放到SEO公众号的,这次显得有点不够严谨。入选的唯一牵强理由,也许和Shopify老大那条推有关把:D

什么是Robots.txt文件?
Robots.txt 文件是我们向 Google、Bing等其他搜索引擎爬虫提供有关抓取哪些网页和资源以及不抓取哪些网页和资源的说明的地方。
robots.txt 文件通常会指示网络爬虫不要爬取内部管理或登录页面。
某in/robots.txt
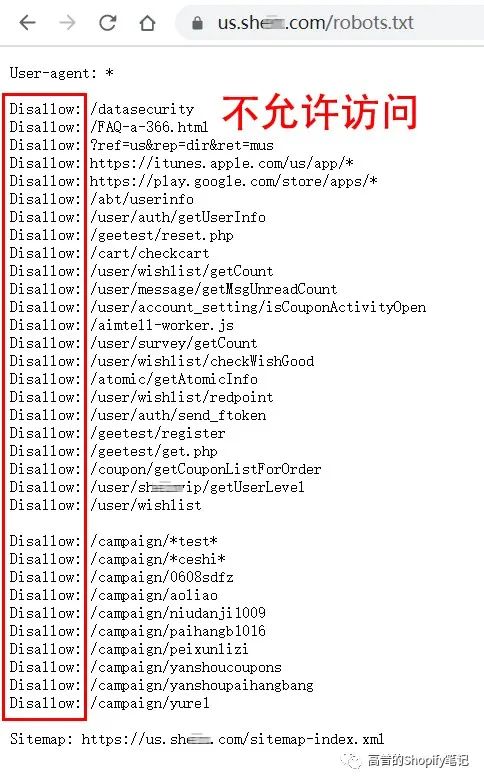
本来想到的是拿spaceX来举例,结果https://www.spacex.com/robots.txt 不显示,不知道怎么回事。如何实现的?求大佬告知!
Robots.txt文件位于什么地方?
robots.txt 文件位于 Shopify 店铺主域名的根目录中。https://us.a*ker.com/robots.txt
Robots.txt由哪几个部分组成?
User-agent:
Disallow:
Sitemap:
所有 Shopify 店铺都有一个默认的 robots.txt 文件,但是,如果想对默认文件进行更改,则可以添加 robots.txt.liquid 模板以进行。
可以对Robots.txt文件进行哪些编辑?
1. 允许或禁止某些 URL 被抓取
2. 为某些爬虫添加抓取延迟规则
3. 添加额外的网站地图 URL
4. 阻止某些爬虫
再具体点,如何操作?
首先新建一个robots.txt.liquid文件
如图:
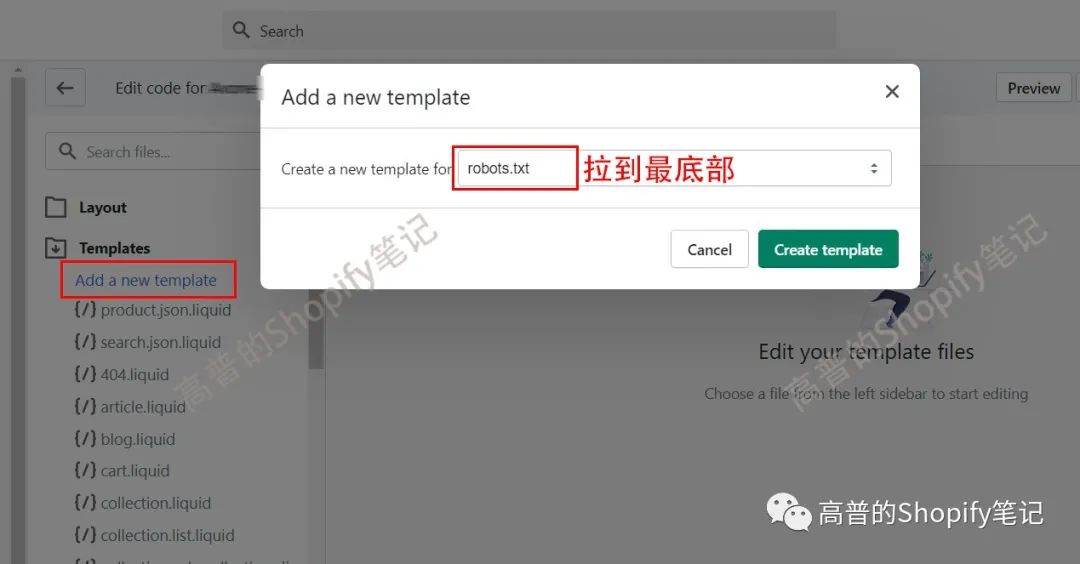
新建的robots.txt.liquid文件

编辑1:Add a new rule to an existing group 向现有组添加新规则
{% for group in robots.default_groups %}{{- group.user_agent }}{%- for rule in group.rules -%}{{ rule }}{%- endfor -%}{%- if group.user_agent.value == '*' -%}{{ 'Disallow: /*?q=*' }}{%- endif -%}{%- if group.sitemap != blank -%}{{ group.sitemap }}{%- endif -%}{% endfor %}
这些代码是啥意思啊?
批量添加我会!{{ 'Disallow: /*?q=*' }}再复制一行
不懂的话,直接复制粘贴到我们新建的新建的robots.txt.liquid文件里面。然后,回到网站前端,域名/robots.txt 刷新下。boom
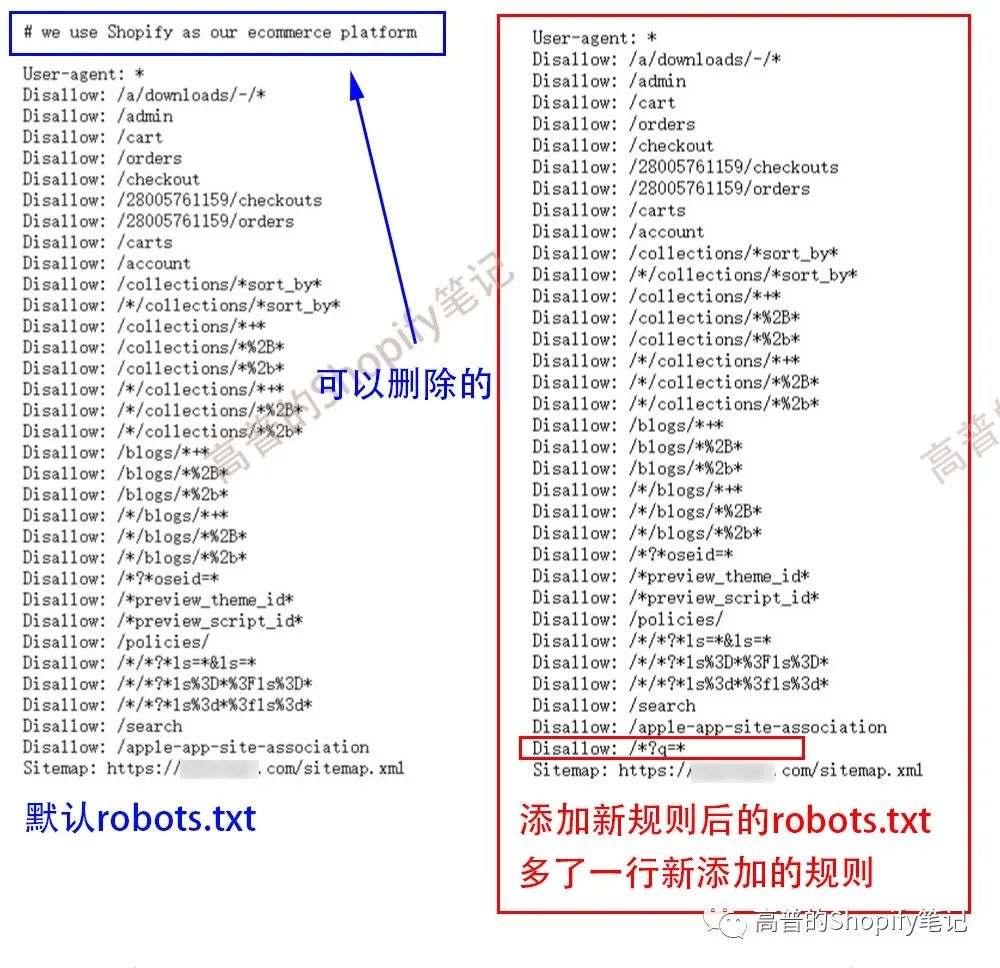
之前我还在想,这次shopify robots.txt更新,可以用这个方法查看网站是否是用shopify搭建,还是太天真了,"# we use Shopify as our ecommerce platform" 这句话,可以编辑修改删除了,哈哈。
可扩展的玩法好多,比如问候下竞争对手:What's your name? what? What is your name? Tony. f**k you Tony.. :DDDD
编辑2:Remove a rule from an existing group 从现有组中删除规则
例如,我们可以使用以下内容删除阻止爬虫访问 /policies/ 页面的规则:
{% for group in robots.default_groups %}{{- group.user_agent }}{%- for rule in group.rules -%}{%- unless rule.directive == 'Disallow' and rule.value == '/policies/' -%}{{ rule }}{%- endunless -%}{%- endfor -%}{%- if group.sitemap != blank -%}{{ group.sitemap }}{%- endif -%}{% endfor %}
←←←向左滑动代码←←←
其实,我最想删除的是,删除阻止爬虫访问 /blog/ 页面的规则:
代码如下:
{% for group in robots.default_groups %}{{- group.user_agent }}{%- for rule in group.rules -%}{%- unless rule.directive == 'Disallow' and rule.value == '/blogs/*+*' -%}{{ rule }}{%- endunless -%}{%- endfor -%}{%- if group.sitemap != blank -%}{{ group.sitemap }}{%- endif -%}{% endfor %}
对了,此语法只删除了第一个Disallow: /blogs/*+*
后面5个,由于不会批量语法,没删除掉,
Disallow: /blogs/*%2B*
Disallow: /blogs/*%2b*
Disallow: /*/blogs/*+*
Disallow: /*/blogs/*%2B*
Disallow: /*/blogs/*%2b*
此处流下了没有代码技术的汗水,请程序员大佬带带我。谢谢!


也不知道,shopify robots.txt默认阻止爬虫访问 /blog/ 页面的规则,该不该删除,求SEO大佬解惑。
编辑3:Add custom rules 添加自定义规则
如果要添加不属于默认组的新规则,则可以在 Liquid 之外手动输入规则以输出默认规则。
Block certain crawlers 阻止某些爬虫
如果爬虫不在默认规则集中,我们可以手动添加规则来阻止它。例如,以下内容将允许您阻止 discobot 爬虫:
<!-- Liquid for default rules -->User-agent: discobotDisallow: /
什么时候用?什么时候发现数据被某些非法的或者恶意的爬虫,爬取网站数据的时候,用!
编辑4:Add extra sitemap URLs添加额外的站点地图 URL
<!-- Liquid for default rules -->Sitemap: [sitemap-url]
到这里,我还真没想到Robots.txt协议会引申出这么多内容,比如Robots.txt文件里面的adsbot-google(以后单独研究下)和Crawl-delay(这次简单挖挖她)
我理解的,Robots.txt协议其实就是一张菜谱,给饥渴的网络爬虫们准备的。
什么是Web Crawler网络爬虫呢?
Web Crawler网络爬虫,也称为搜索引擎蜘蛛spider或者机器人bot,是一种自动化软件,其任务是发现和扫描网页和资源,目的是在给定的搜索引擎上将它们编入索引。
Googlebot是Google 网络爬虫的通用名称。Googlebot是两种不同类型爬虫的总称:一种是模拟桌面用户的桌面爬虫,另一种是模拟移动设备上用户的移动爬虫。
蜘蛛访问任何一个网站的时候,都会先访问网站根目录下的Robots.txt文件,如果Robots.txt禁止搜索引擎抓取某些文件或者目录,蜘蛛将会遵守协议,不抓取被禁止的网址。
比如:
Disallow: /admin
Disallow: /checkout
Disallow: /carts
Disallow: /orders
什么是网页爬行?
这是网络爬虫自动获取网页或资源的过程,目的是在给定的搜索引擎上对其进行索引。
搜索引擎蜘蛛访问网站页面时类似于普通用户使用的浏览器,蜘蛛程序发出页面访问请求后,服务器返回HTML代码,蜘蛛程序把收到的代码存入原始页面数据库。
搜索引擎为了提高爬行和crawl rate抓取速度,往往会使用多个蜘蛛并发分布爬行。
什么是Crawl-Delay抓取延迟?
Crawl-Delay指令是一个非官方指令,旨在与爬虫通信以减慢爬行速度,以免网络服务器过载。
其实,有些搜索引擎是不支持 crawl-delay 指令的,并且 crawl-delay 指令的解释方式因搜索引擎而异。
比如,Google就不支持crawl-delay 指令,如果你想要求谷歌爬得慢一些,你需要在谷歌搜索控制台中设置crawl rate抓取速度。
如果你的网站无法跟上Google的抓取请求,可以请求更改crawl rate抓取速度。
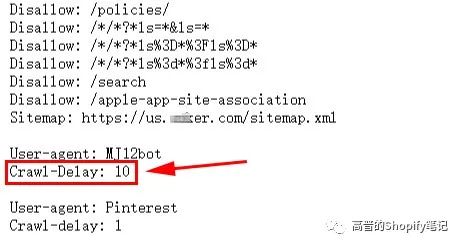
本篇就不讨论如何修改这个值了,作为一般玩家的我也用不到。以后用到的时候再单独拿出来研究。
"crawl-delay" = "crawl rate" = 抓取速度
什么是Crawl Rate抓取速度?
抓取速度是指Googlebot在抓取网站时每秒向网站发出的请求次数,例如每秒发出 5 次请求。
我们无法更改Google抓取网站的频率,但如果希望Google抓取网站上的新内容或更新后的内容,可以请求重新抓取。
抓取速度的正确用法:
Google 采用先进的算法来确定最佳的网站抓取速度。我们的目标是,每次访问我们的网站时,在不导致服务器带宽过载的情况下尽可能多地抓取网页。
如果 Google 每秒向网站发出的请求过多,导致服务器的速度下降,我们可以限制 Google 抓取网站的速度。限制对根级网站(例如 www.example.com 和 http://subdomain.example.com)的抓取速度。设置的抓取速度是 Googlebot 的抓取速度上限。请注意,Googlebot 并不一定会达到这一上限。
除非发现服务器出现负载问题并确定该问题是由于 Googlebot 过于频繁地访问我们的服务器导致的,否则不要限制抓取速度。
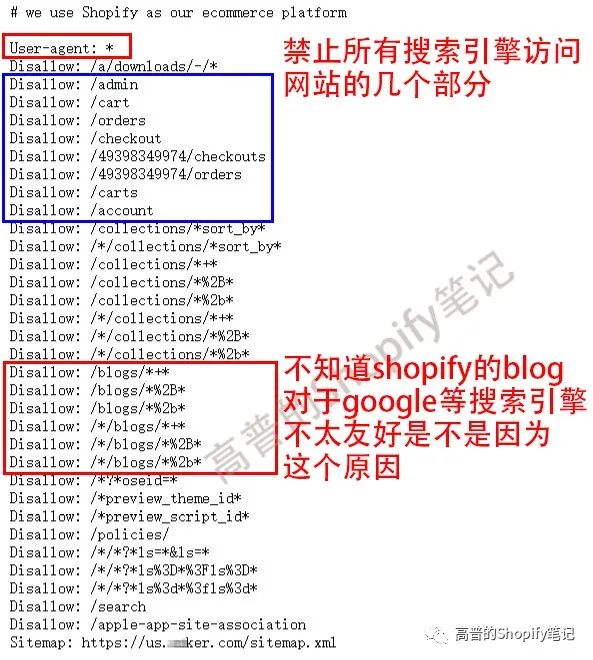
robots.txt常见的语法
禁止所有搜索引擎访问网站的几个部分(下图中的01、02目录)
User-agent: *
Disallow: /01/
Disallow: /02/
禁止爬虫抓取cart、checkout、orders数据还是很好理解把(客户的隐私,其实搜索引擎拿来没什么用,不过竞争对手非常喜欢)。不过!为啥默认不让抓取blog数据,确实有点想不明白,请SEO大佬解惑。

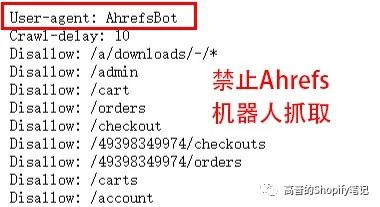
禁止某个搜索引擎的访问(下例中的AhrefsBot)
User-agent: AhrefsBot
Disallow: /
有关更多robots.txt的语法,请移步《最详细的robots.txt写法大全》,以后能找得到现成的、我看得上的中文基础解释,就直接引用,省事!
对了,最后来个友情广告。事情是这样的。
直接上联系方式

小点声:
Bing优势!现在竞争不大,bid低。
Bing劣势!有点挑类目。
早布局,早省心!
以上Shopify如何编辑Robots.txt协议文件仅代表个人喜好,仅供参考!
长按下图二维码关注,给我留言或加我好友。


为了让读者朋友们更加方便地交流和分享,我建立了一个纯交流群
(2个公众号共用这一个群)<高普的SEO笔记>,真诚地邀请各位独立站的大佬们加入进来,相互交流学习和分享。
PS:服务商朋友勿加(感谢您的理解)
加我微信:valentine06
备注:shopify 进群
如果这篇文章能帮助到您,请点赞、转发加关注!谢谢您!
"听说打赏的人,明年别墅靠海喔"
[1]. How to Edit Shopify Robots.txt File
https://increasily.com/how-to-edit-shopify-robots-txt-file/
[2]. Our Top CEOs: Meet 30 Leaders Who Turned Crisis Into Opportunity
https://www.barrons.com/articles/top-ceos-2021-51624667968
[3]. Googlebot
https://developers.google.com/search/docs/advanced/crawling/googlebot
[4]. The ultimate guide to robots.txt
https://yoast.com/ultimate-guide-robots-txt/
[5]. What does crawl-delay: 10 mean in robots.txt?
https://www.contentkingapp.com/academy/robotstxt/faq/crawl-delay-10/
[6]. Change Googlebot crawl rate
https://support.google.com/webmasters/answer/48620
[7]. Discover How Google Search Works
https://www.google.com/search/howsearchworks/
[8]. Editing robots.txt.liquid
https://help.shopify.com/en/manual/promoting-marketing/seo/editing-robots-txt
[9]. Ask Google to recrawl your URLs
https://developers.google.com/search/docs/advanced/crawling/ask-google-to-recrawl
[10]. Hiding a page from search engines
https://help.shopify.com/en/manual/promoting-marketing/seo/hide-a-page-from-search-engines
[11]. Editing robots.txt.liquid
https://help.shopify.com/en/manual/promoting-marketing/seo/editing-robots-txt
[12]. Customize robots.txt
https://shopify.dev/themes/seo/robots-txt
[13]. Discourse (software)
https://en.wikipedia.org/wiki/Discourse_(software)
[14]. Create a robots.txt file
https://developers.google.com/search/docs/advanced/robots/create-robots-txt
[15]. robots.txt.liquid
https://shopify.dev/themes/architecture/templates/robots-txt-liquid
[16]. How to Edit robots.txt on Shopify Stores?
QgB7Y8NNmDw
文章为作者独立观点,不代表DLZ123立场。如有侵权,请联系我们。( 版权为作者所有,如需转载,请联系作者 )

网站运营至今,离不开小伙伴们的支持。 为了给小伙伴们提供一个互相交流的平台和资源的对接,特地开通了独立站交流群。
群里有不少运营大神,不时会分享一些运营技巧,更有一些资源收藏爱好者不时分享一些优质的学习资料。
现在可以扫码进群,备注【加群】。 ( 群完全免费,不广告不卖课!)






发表评论 取消回复