谷歌研究论文(文章底部有论文原文链接)描述了一个叫 TW-BERT 的出色框架,无需重大更改即可提高搜索排名。
§TW-BERT 是一个端到端查询词权重框架,它连接两种范式改善搜索结果
§与现有查询扩展模型集成,并提高性能
§部署该框架需要更少更改
谷歌宣布了一个名为Term Weighting BERT(TW-BERT) 的优秀的排名框架,它可以改善搜索结果,并且易于在现有排名系统中进行部署。
尽管谷歌尚未确认它正在使用 TW-BERT,但这个新框架是一个突破,它全面改进了排名流程,包括查询扩展。它也很容易部署,在我看来,这使得它更有可能被使用。
TW-BERT 有许多共同作者,其中包括Google DeepMind 杰出研究科学家、Google Research 前研究工程高级总监Marc Najork 。Marc Najork与人合著了许多与排名过程相关的主题和许多其他领域的研究论文。
Marc Najork 被列为合著者的论文包括:
关于优化神经排序模型的 Top-K 指标 – 2022
用于不断发展的内容的动态语言模型 – 2021
重新思考搜索:让业余爱好者成为领域专家 – 2021
神经排序模型的特征转换 – – 2020
在 TF-Ranking 中使用 BERT 学习排名 – 2020
长篇文档的语义文本匹配 – 2019
TF-Ranking:用于学习排序的可扩展 TensorFlow 库 – 2018
用于排名指标优化的 LambdaLoss 框架 – 2018
学习在个人搜索中利用选择偏差进行排名 - 2016
什么是 TW-BERT?
TW-BERT 是一个排名框架,它为搜索查询中的单词分配分数(称为权重),以便更准确地确定哪些文档与该搜索查询相关。TW-BERT 在查询扩展中也很有用。
查询扩展是一个重述搜索查询或向其添加更多单词(例如将单词“recipe”添加到查询“chicken soup”)以更好地将搜索查询与文档匹配的过程。向查询添加分数有助于更好地确定查询的内容。
TW-BERT 连接两种信息检索范式
该研究论文讨论了两种不同的搜索方法。一种是基于统计的,另一种是深度学习模型。
接下来讨论了这些不同方法的优点和缺点,并提出 TW-BERT 是一种弥合这两种方法且没有任何缺点的方法。
论文提到:
“These statistics based retrieval methods provide efficient search that scales up with the corpus size and generalizes to new domains.
“这些基于统计的检索方法提供了有效的搜索,可以随着语料库的大小进行扩展并推广到新的领域。
However, the terms are weighted independently and don’t consider the context of the entire query.”
然而,这些术语是独立加权的,并且不考虑整个查询的上下文。”
研究人员随后指出,深度学习模型可以找出搜索查询的上下文。
解释如下:
“For this problem, deep learning models can perform this contextualization over the query to provide better representations for individual terms.”
“对于这个问题,深度学习模型可以对查询执行上下文化,以便为各个术语提供更好的表示。”
研究人员建议使用 TW-Bert 来连接这两种方法。
该突破性描述是这样的:
“We bridge these two paradigms to determine which are the most relevant or non-relevant search terms in the query…
“我们将这两种范式联系起来,以确定查询中哪些是最相关或不相关的搜索词......
Then these terms can be up-weighted or down-weighted to allow our retrieval system to produce more relevant results.”
然后可以提高或降低这些术语的权重,以使我们的检索系统能够产生更相关的结果。”
TW-BERT 搜索词权重示例
该研究论文提供了搜索查询“Nike running Shoes”的示例。简单来说,“Nike running Shoes”这个词是排名算法必须按照搜索者想要理解的方式来理解的三个词。他们解释说,强调查询的“running”部分会显示包含耐克以外品牌的不相关搜索结果。在该示例中,品牌名称 Nike 很重要,因此排名过程应要求候选网页中包含“Nike”一词。
候选网页是正在考虑用于搜索结果的页面。TW-BERT 的作用是为搜索查询的每个部分提供一个分数(称为权重),以便它以与输入搜索查询的人有相同意义的方式。在这个例子中,Nike这个词被认为很重要,所以应该给它一个更高的分数(权重)。
论文提到:
“Therefore the challenge is that we must ensure that Nike” is weighted high enough while still providing running shoes in the final returned results.”
“因此,挑战在于我们必须确保“Nike”的权重足够高,同时在最终返回的结果中仍然提供running shoes。”
另一个挑战是理解“running”和“shoes”这两个词的上下文,这意味着将这两个词连接为短语“running shoes”时,权重应该更高,而不是分别设置这两个词的权重。
解释如下:
“The second aspect is how to leverage more meaningful n-gram terms during scoring.
“第二个方面是如何在评分过程中利用更有意义的 n-gram语法术语。
In our query, the terms “running” and “shoes” are handled independently, which can equally match “running socks” or “skate shoes”.
在我们的查询中,术语“running”和“shoes”是独立处理的,它们同样可以匹配“running socks”或“skate shoes”。
In this case, we want our retriever to work on an n-gram term level to indicate that “running shoes” should be up-weighted when scoring.”
在这种情况下,我们希望我们的检索器在 n-gram 术语级别上工作,以表明“running shoes”在评分时应该增加权重。”
解决当前框架的局限性
该研究论文总结了传统的加权在查询变化方面的局限性,并提到那些基于统计的加权方法在零样本场景中表现不佳。零样本学习是指模型解决未经训练的问题的能力。
还总结了当前术语扩展方法固有的局限性。术语扩展是指使用同义词来查找搜索查询的更多答案或推断另一个单词时。例如,当有人搜索“chicken soup”时,它会被推断为“chicken soup recipe”。
论文当前方法的缺点:
“…these auxiliary scoring functions do not account for additional weighting steps carried out by scoring functions used in existing retrievers, such as query statistics, document statistics, and hyperparameter values.
“......这些辅助评分函数不考虑现有检索器中使用的评分函数执行的额外加权步骤,例如查询统计、文档统计和超参数值。
This can alter the original distribution of assigned term weights during final scoring and retrieval.”
这可能会改变最终评分和检索期间分配的术语权重的原始分布。”
接下来,研究人员表示,深度学习有其自身的复杂性,即部署它们的复杂性以及当它们遇到未经过预先训练的新领域时的不可预测的行为。这就是 TW-BERT 发挥作用的地方。
TW-BERT 连接两种方法
它所提出的解决方案类似于混合方法。在下面的引用中,术语 IR 表示信息检索。
论文提到:
“To bridge the gap, we leverage the robustness of existing lexical retrievers with the contextual text representations provided by deep models.
“为了弥补这一差距,我们利用现有词汇检索器的稳健性和深度模型提供的上下文文本表示。
Lexical retrievers already provide the capability to assign weights to query n-gram terms when performing retrieval.
词汇检索器已经提供了在执行检索时为查询n-gram语法术语分配权重的功能。
We leverage a language model at this stage of the pipeline to provide appropriate weights to the query n-gram terms.
我们在这个阶段利用语言模型为查询n-gram词项提供适当的权重。
This Term Weighting BERT (TW-BERT) is optimized end-to-end using the same scoring functions used within the retrieval pipeline to ensure consistency between training and retrieval.
该术语加权 BERT (TW-BERT) 使用检索使用的相同评分函数进行端到端优化,以确保训练和检索之间的一致性。
This leads to retrieval improvements when using the TW-BERT produced term weights while keeping the IR infrastructure similar to its existing production counterpart.”
当使用 TW-BERT 生成的术语权重时,这会导致检索改进,同时保持 IR 基础设施与其现有的对应产品相似。”
TW-BERT 算法为查询分配权重,以提供更准确的相关性分数,然后排名过程的其余部分可以使用该分数。
 术语加权检索 (TW-BERT)
术语加权检索 (TW-BERT)
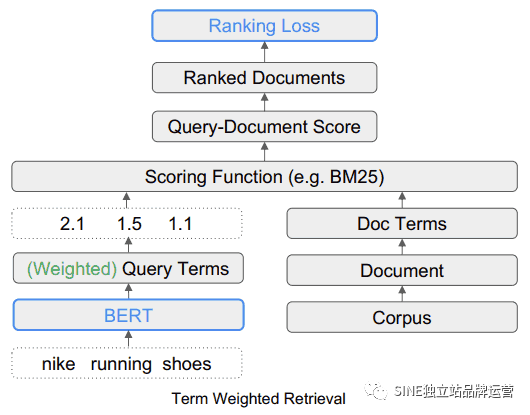
TW-BERT 易于部署
TW-BERT 的优点之一是它可以像一个插入组件一样直接插入到当前的信息检索排序过程中。
“这使我们能够在检索期间直接在 IR 系统中部署术语权重。这与之前的加权方法不同,后者需要进一步调整检索器的参数以获得最佳检索性能,因为它们优化通过启发式获得的术语权重,而不是优化端到端。”这种易于部署的重要之处在于,不需要专门的软件或硬件更新即可将 TW-BERT 添加到排名算法过程中。
Google 在其排名算法中使用 TW-BERT 吗?
如前所述,部署 TW-BERT 相对容易。在我看来,可以合理地假设,部署的简便性增加了该框架被添加到 Google 算法中的可能性。这意味着谷歌可以将 TW-BERT 添加到算法的排名部分,而无需进行全面的核心算法更新。
除了易于部署之外,在猜测算法是否可以使用时要寻找的另一个质量是该算法在改进当前技术水平方面的成功程度。有许多研究论文只取得了有限的成功或没有任何改进。这些算法很有趣,但可以合理地假设它们不会进入谷歌的算法。令人感兴趣的是那些非常成功的,TW-BERT 就是这种情况。
TW-BERT 非常成功。他们表示,很容易将其放入现有的排名算法中,并且其性能与“密集神经排名器”一样好。
论文解释了它如何改进当前的排名系统:
“Using these retriever frameworks, we show that our term weighting method outperforms baseline term weighting strategies for in-domain tasks.
“使用这些检索器框架,我们表明我们的术语加权方法优于领域内任务的基线术语加权策略。
In out-of-domain tasks, TW-BERT improves over baseline weighting strategies as well as dense neural rankers.
在域外任务中,TW-BERT 改进了基线加权策略以及密集的神经排序器。
We further show the utility of our model by integrating it with existing query expansion models, which improves performance over standard search and dense retrieval in the zero-shot cases.
我们通过将模型与现有的查询扩展模型集成来进一步展示模型的实用性,这在零样本情况下提高了标准搜索和密集检索的性能。
This motivates that our work can provide improvements to existing retrieval systems with minimal onboarding friction.”
这促使我们的工作能够以最小的基础来改进现有的检索系统。”
这就是 TW-BERT 可能已经成为 Google 排名算法一部分的两个充分理由。
1.这是对当前排名框架的全面改进
2.易于部署
如果 Google 部署了 TW-BERT,那么这可能可以解释 SEO 监控工具和搜索营销社区成员在过去一个月报告的排名波动。一般来说,谷歌只会宣布一些排名变化,特别是当它们造成明显影响时,例如谷歌宣布 BERT 算法时。在没有官方确认的情况下,我们只能推测 TW-BERT 是 Google 搜索排名算法一部分的可能性。
尽管如此,TW-BERT 是一个了不起的框架,它似乎提高了信息检索系统的准确性,并且可以被谷歌使用。
翻译整理作品, 原文作者:Roger Montti
文章中提到的论文原文在这里:https://marc.najork.org/pdfs/kdd2023-twbert.pdf
文章为作者独立观点,不代表DLZ123立场。如有侵权,请联系我们。( 版权为作者所有,如需转载,请联系作者 )

网站运营至今,离不开小伙伴们的支持。 为了给小伙伴们提供一个互相交流的平台和资源的对接,特地开通了独立站交流群。
群里有不少运营大神,不时会分享一些运营技巧,更有一些资源收藏爱好者不时分享一些优质的学习资料。
现在可以扫码进群,备注【加群】。 ( 群完全免费,不广告不卖课!)





发表评论 取消回复