
1.1 Googlebot 到底怎么“发现”网页?
外链、站内链接、XML Sitemap、GSC 主动提交等。
运营可以做的动作:
| 主动向谷歌提交具体网址 (针对单个页面) | Google Search Console → 页面索引 → 检查 URL | |
| 利用外部链接 | 将网页链接到其他网站,做高质量外链 | 高质量外部网站的链接能加快你的页面被发现的速度 |
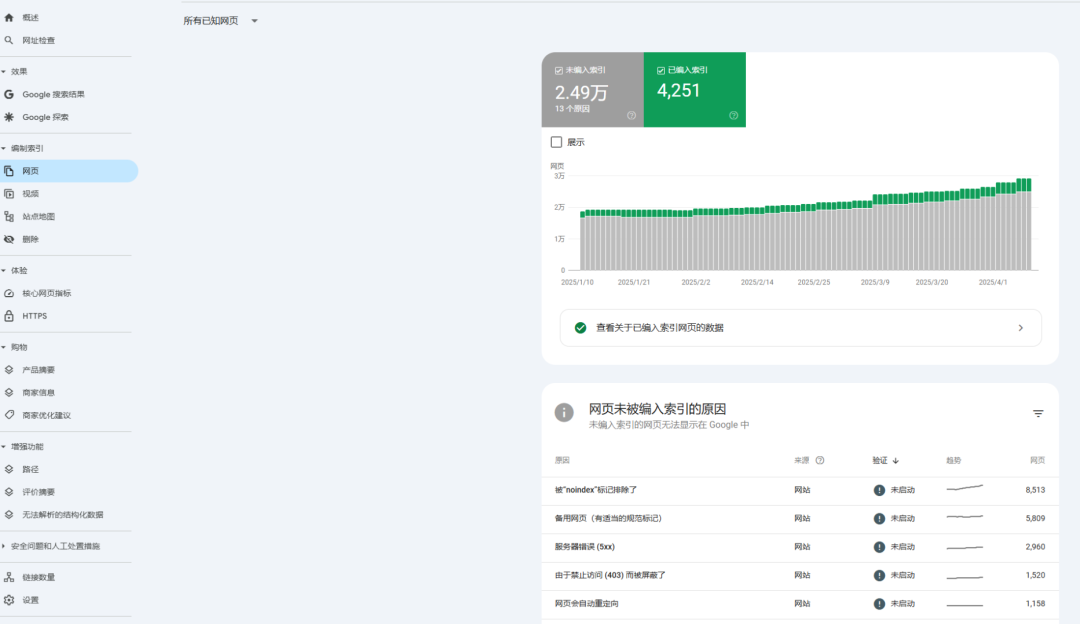
索引的本质:Google 会分析网页上的文本、图片和视频文件,并将信息存储在大型数据库 Google 索引中,也就是说抓取网页后,Google 会尝试了解该网页的内容,并决定是否编入索引。我们要做的核心,让Google理解并认可网页内容。
提升索引率的 4 个关键
是否会编入索引还取决于网页内容质量:避免内容质量低,重复、拼凑、无价值信息。优化网页结构与内容质量(E-E-A-T)
Google讨厌重复内容:如果是同一内容:指定一个主版本也就是“规范网页”Canonical Page;如果是相似内容:合并或重写,让每篇都有独特信息
结构化数据:Product、FAQ、Breadcrumb… 让搜索引擎迅速理解实体关系。
页面信号:网站语言,目标国家和地区,货币等等,这些信息会影响网页在搜索结果中的表现,比如你的网站专门服务美国用户,Google 会倾向于在美国搜索中显示。
Core Web Vitals:LCP≤2.5 s、CLS≤0.1、INP≤200 ms,Google 倾向收录极速页面。
自查技巧:在 GSC「页面索引 → 为什么无法索引」中查看“发现但未索引”“已爬取-目前未索引”等原因,对症下药。
Canonical Page举例说明:
基本产品页:
https:/anker.com/products/mago (规范网页)
分页或筛选引发的变种页面
https://anker.com/collections/wireless/products/mango
这其实是同一个产品页,Google 不会把所有都显示在搜索结果里,而是自动在这组中挑出“最有代表性”的一个,作为规范网页(Canonical Page),这个规范网页才有机会出现在搜索结果中,当然,也可以人为指定哪个页面是规范化页面,只需要在网页 <head> 中添加如下代码:<link rel="canonical" href="https://example.com/product">
三、呈现 & 排名(Serve & Rank)——让好内容上首页
呈现搜索结果:当用户在 Google 中搜索时,Google 会返回与用户查询相关的信息。
相关性:关键词=用户意图?页面主题是否匹配?用户地理位置,用户使用语言等等
质量:E-E-A-T⚙️(经验 Experience、专业性 Expertise、权威性 Authoritativeness、可信度 Trust)+ 内容深度。
可用性:加载速度、移动端体验、HTTPS、安全声明、可访问性。
被收录 ≠ 能搜到,关键要让Google认为你的页面质量高+符合用户搜索意图
提升页面质量分的小技巧
Sitemap 已提交且每日自动更新
robots.txt 未屏蔽重要目录
关键模板(首页/分类/文章页)标题唯一 & 含关键词
Core Web Vitals 均达标
主要页面已加结构化数据
作者信息 & 更新日期清晰可见
外链增长、404 清理、服务器状态周周跟踪
五、结语 & 下期看点
至此,你已经完整拆解了搜索引擎的三步魔法。
下一篇,我们将进入「Technical SEO 实战」。
文章为作者独立观点,不代表DLZ123立场。如有侵权,请联系我们。( 版权为作者所有,如需转载,请联系作者 )

网站运营至今,离不开小伙伴们的支持。 为了给小伙伴们提供一个互相交流的平台和资源的对接,特地开通了独立站交流群。
群里有不少运营大神,不时会分享一些运营技巧,更有一些资源收藏爱好者不时分享一些优质的学习资料。
现在可以扫码进群,备注【加群】。 ( 群完全免费,不广告不卖课!)







发表评论 取消回复