点击上方蓝字

如果训练语料开始“计价”,
如果内容访问从“默认抓取”变成“协商授权”,
你现有的SEO策略、内容预算和品牌可见性,还能照原样延续多久?
就在本月,Cloudflare 最近为 AI 爬虫引入了一个变量——它不是一个功能更新,而是一次制度层的松动信号。
它不大张旗鼓,但足够关键。
它影响的是:谁可以读你的内容,AI是否理解你,你是否能出现在答案里。
重点速览:
•Cloudflare 正式支持网站对 AI 爬虫“按次收费”,通过 HTTP 402 响应设定访问权限与定价;•这是内容抓取历史上首次具备“制度化变现”能力,访问权不再天然开放;•SEO 排名机制短期内未变,但“爬虫能否访问”成为新的策略接口;•GEO 可见性开始依赖于“是否出现在训练数据中”,不是“有没有被实时搜索到”;•内容策略从“怎么发”开始转向“谁能看、是否能被理解与引用”;•AI时代的内容分发权,正从平台主导逐步转向内容拥有者手中。
目录
一、AI爬虫带来的流量困境,已经浮出水面
二、Pay Per Crawl 到底改了什么?
三、重点:对传统SEO的影响
四、重点:对GEO的影响
五、从“爬虫付费”走向“智能代理付费”?一些值得提前思考的演化方向
六、写在最后
一、AI爬虫带来的流量困境,已经浮出水面
过去几年,AI模型大规模抓取网站内容,却几乎不带来流量。
这打破了网站用内容换流量的旧逻辑。
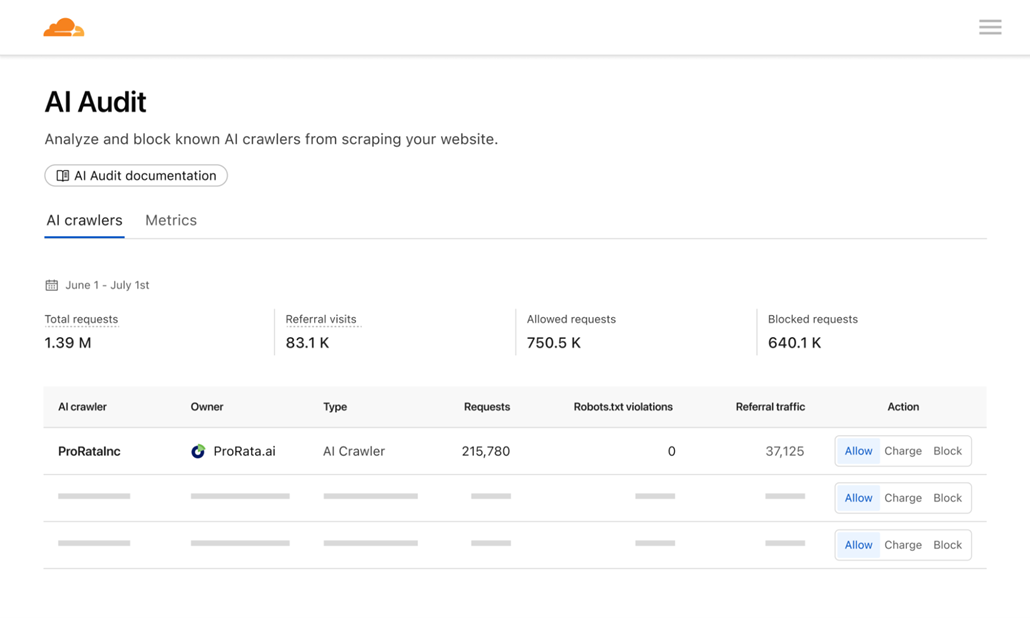
光是 GPTBot,就已经访问了 Cloudflare 网络中超过 40% 的网站。
但几乎没有站点收到对应的访问。
根据 Cloudflare 公布的数据,GPTBot 和 ClaudeBot 的抓取与访问比例分别达到 1,500:1 和 60,000:1,而 Google 也从6:1升至18:1。
内容被爬走了,但用户没有来。
受影响最明显的是依赖自然流量的网站,例如:
•内容型独立站•高客单价品牌站(如 DTC)•广告变现平台与媒体
对这些站点来说,流量流失直接影响收入,不只是SEO排位的问题。
同时,大多数网站对AI爬虫的访问行为毫无感知,更谈不上控制和定价。
Cloudflare 选择在这一节点介入,试图用一种技术机制,重建AI爬虫与内容方之间的关系。
二、Pay Per Crawl 到底改了什么?
为了节省时间给后面重点内容,我们在这里只大致讲一下 Pay Per Crawl 的实现方式,具体技术手段感兴趣的可以到官网自行查看。
Cloudflare 推出的 Pay Per Crawl,不是一个新的协议,也不是重新设计互联网的结构。
它是在现有网页抓取流程上,加了一层“收费控制“。
每当 AI 爬虫访问页面时,网站可以返回一个 HTTP 402 响应,告诉对方:这份内容不是免费提供的,需付费才能继续访问。
如果爬虫愿意支付,则通过支付请求重新访问,服务器返回正常内容。
如果不愿支付,访问就被拒绝。
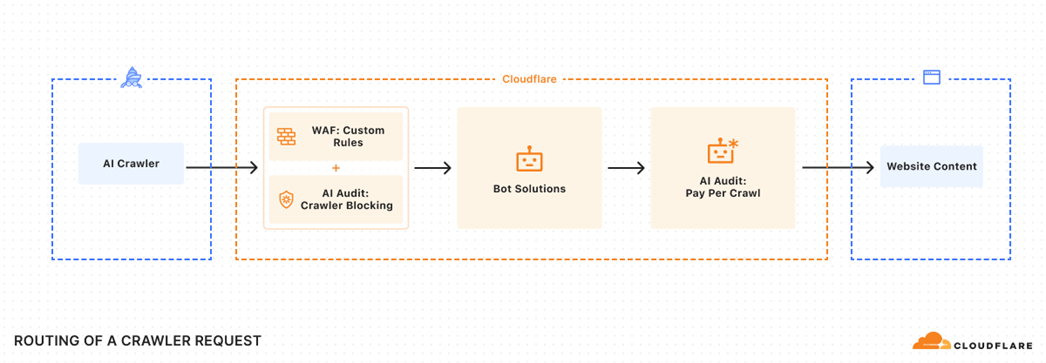
网站可以自行决定对不同爬虫的处理方式:
允许、收费、或直接拒绝。
Cloudflare 提供的是这套机制的底层能力,内容方通过配置,即可启用。
这背后的变化有两个关键点:
一是默认状态被打破。
以前,只要有抓取能力,AI 爬虫就能读取全站内容,且站点默认不设限制。
现在,站点开始具备“收费控制权”。
二是执行门槛被大幅降低。
以前想对 AI 收费,需要技术能力、协商管道、定制接口,几乎没人能做到。
而 Cloudflare 本身是全球最主流的 CDN 之一,覆盖超过 20% 的网站,同时还确切地知道都有哪些机器人正在这些网站以及访问频率,直接插入抓取路径。
也就是说,内容方第一次可以在不改变现有网站结构的前提下,对 AI 的访问行为设限并建立价格锚点。
是否选择收费是另一回事,但“可以收费”这件事,已经被摆在桌面上了。
三、重点:对传统SEO的影响
搜索引擎的访问权,第一次出现“制度化”的可能。
Cloudflare这次上线的 Pay Per Crawl,让“允许谁抓取内容”这件事,从默认开放,变成了可控、可设限、甚至可定价的资源管理。
目前,它并未限制Googlebot、Bingbot等搜索引擎爬虫的访问。
主流网站短期内也不太可能主动收费或封锁,这是出于对自然流量的现实依赖。
但底层规则,变了。
过去,搜索引擎与站点之间是一种隐性的互利结构:
你让我抓内容,我给你带流量。
如今,“抓取”这件事第一次被赋予了交易属性,意味着搜索引擎的“免费访问权”不再天然合理。
站在更高维度看,这是SEO十几年来,第一次在技术基础层出现议价空间。
而这,可能是影响未来搜索生态的一个关键转折点。
微观来看,SEO操作短期内不会失效。
Google仍然是许多站点自然流量的大头,权重高、机制稳定,依然值得投入。
但已经有信号说明,这套机制的边界,正在松动。
搜索结果页的AI摘要内容正逐步前置,内容更新带来的流量反馈周期在拉长,爬虫频率越来越高,但实际带来的流量却越来越“稀薄”。
内容被读取,但未必被分发,更谈不上被点击。
这并非Cloudflare造成,但Pay Per Crawl的出现,强化了一个趋势:
内容方有可能重新掌握一部分分发权。
如果未来,搜索引擎也被纳入“可设规则、可谈访问”的范围,
SEO将不仅仅是“内容优化”,而是内容资产管理的一部分。
robots.txt不再只是权限开关,而是需要基于“内容价值+爬虫回报率”去策略性配置的接口。
收费还是免费、授权还是封禁、部分放开还是分阶段策略……
这些议题过去从未进入SEO日常操作范畴,而现在,开始变得有现实意义。
这对内容密集型、SEO依赖度高的站点来说,是需要被关注的结构性变化。
四、重点:对GEO的影响
你在不在AI答案里,可能取决于你有没有“出现在训练数据里”。
当前主流AI搜索的生成机制,普遍包括两个阶段:
一是训练阶段,
AI爬虫抓取网页、文档、结构化内容,构建语言模型的基础能力和知识框架。
二是实时检索,
模型在用户发问时,通过搜索接口获取最新内容补充回答。
很多网站认为只要没有屏蔽Bing、Google,模型就能看到自己,自然会被纳入回答。
但这中间隔了一道机制层的差异。
训练阶段决定了模型理解语言、识别权威、组织答案等的“认知习惯”;
而实时检索只是临时提供信息片段,
它并不能改变模型对内容结构、权重或风格的判断偏好。
这也是Pay Per Crawl带来的潜在影响所在。
Cloudflare现在允许网站对AI爬虫收费、限制甚至拒绝访问。
这意味着,如果未来越来越多网站设置了访问门槛,AI模型在训练阶段可能抓不到这些内容。
如果模型没见过你,即使实时抓到了你的页面,它也可能无法判断你内容的权威性或抓住真正重点。
更难在回答中选中你、引用你、表达出你希望传达的价值。
GEO的重点,不是让你排在搜索结果页,而是让你进入模型的表达体系,让它“理解你、信任你、会提到你”。
而这一切,很大程度上,取决于训练阶段是否接触过你的内容。
Pay Per Crawl本质上改变的是:
AI能抓到什么,站点能控制什么,训练语料库的构成边界在哪里。
微观来看,
对依赖知识表达、品牌建立、内容可信度的独立站而言,这可能是一个“可被AI理解”的门槛问题。
尤其当你的站点从未出现在训练数据中,哪怕实时被抓取,AI也可能“看不懂”你,或者不主动选你。
宏观来看,
模型语料池如果越来越偏向默认开放、无需付费的内容来源,整个生成生态所依赖的知识基础将更偏向“免费、广义、低结构化”的部分。
这会逐步影响AI所呈现的行业面貌、品牌认知与权威结构。
这一变化不会立刻反映在流量或转化数据上,但它确实正在重塑GEO的底层逻辑。
你是否出现在AI答案中,开始与“训练阶段是否接触过你”挂钩。
这可能是未来内容可见性竞争中,最容易被忽略的一部分。
对于品牌来说,
某种程度上,这可能比你现在排在第几页,更值得关注。
五、从“爬虫付费”走向“智能代理付费”?一些值得提前思考的演化方向
Cloudflare这次启用的是HTTP 402状态码,这是早期为“网络微支付”预留的协议标准之一。
它沉寂多年,如今被重新唤醒,背后不只是为AI爬虫收费,更是为未来更复杂的数据访问模式打开通道。
如果说“付费爬虫”只是第一阶段,接下来可能演化出的方向包括:
•动态定价机制:不同内容、路径、用途设定不同收费标准,例如新闻首页与历史归档,训练用语料与推理调用,价格可能完全不同;•机器对机器的协商机制:AI不再靠预训练“猜”,而是在调用内容时实时协商费用,形成更透明的市场行为;•语义授权与用途分层:同一段内容,训练、问答展示、产品归类,各自许可,各自定价;•代理化内容消费:用户不会主动点击网站,而是通过AI代理程序检索、汇总、支付并消费信息;•统一爬虫身份协议:当前大多数AI爬虫都缺乏标准化身份验证体系,Cloudflare正尝试以签名机制建立访问者的“实名制”。
目前这些机制都处在非常早期的探索阶段。
但它们有一个共同指向:内容不再是只能“开放”或“封闭”的资源,而是一种可以协商、授权、计价、交易的资产。
对行业来说,价值分配机制正在酝酿改变。
这不是结论,而是起点。
六、写在最后
Cloudflare 的 Pay Per Crawl,不只是一次技术机制的更新。
它释放出的信号更值得关注:
内容正从默认暴露,转向可定价、可协商的资产控制。
SEO,不再只是争取排名的技术工作,正向“能否被算法纳入视野”扩展。
GEO,也不仅是AI如何检索你,更关乎它是否理解你、是否愿意表达你。
训练语料、爬虫访问权限、内容分发机制,三者开始联动,并对内容可见性产生实际影响。
内容策略,也不再局限于“发布在哪”“布局哪些关键词”,而是逐步进入“谁能访问、怎么看、用于哪里”的阶段。
这不是某个渠道策略的微调,而是内容资产管理逻辑的转向。
谁能被纳入新一代算法的结构里,谁的分发能力就更可能具备延续性。
这是我们观察这次更新的角度。
它还不是结论,更像是一个开始。
但可以明确的是:
内容权属、访问控制、训练语料之间的连接方式,正在被重构,至少在技术层面已具备现实路径。
这或许将成为未来内容生态中,最底层、也最值得持续关注的结构变量之一。
如果你觉得这篇分析有启发,欢迎点赞、转发、收藏,让更多关注趋势的人看到它。
还没订阅的朋友,可以点一下上方的「订阅」和「置顶」,方便第一时间收到更新,我们每周都会更新类似的专业分享。
另外,欢迎在评论区聊聊你最关心的方向,我们会结合大家的反馈策划后续内容。
文章为作者独立观点,不代表DLZ123立场。如有侵权,请联系我们。( 版权为作者所有,如需转载,请联系作者 )

网站运营至今,离不开小伙伴们的支持。 为了给小伙伴们提供一个互相交流的平台和资源的对接,特地开通了独立站交流群。
群里有不少运营大神,不时会分享一些运营技巧,更有一些资源收藏爱好者不时分享一些优质的学习资料。
现在可以扫码进群,备注【加群】。 ( 群完全免费,不广告不卖课!)







发表评论 取消回复