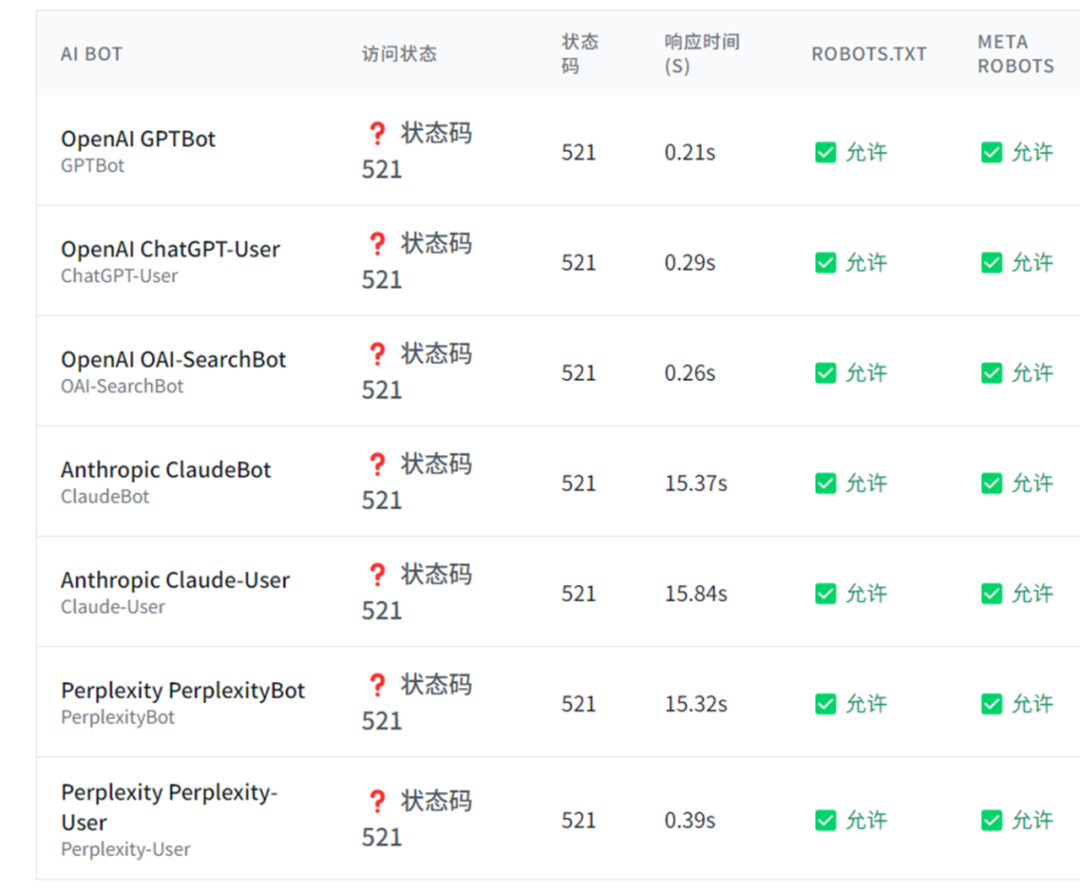
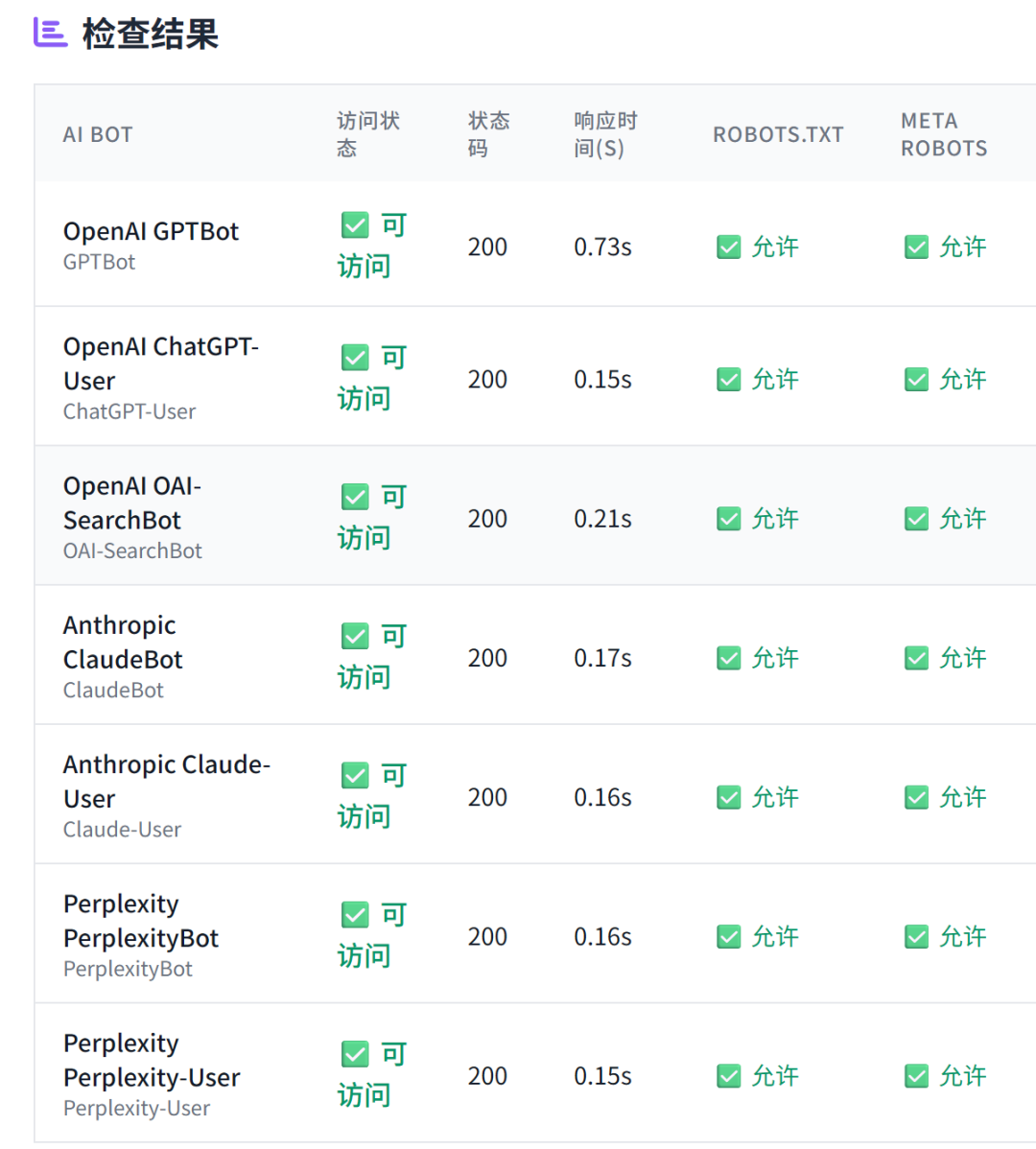
SEO 进化成 GEO 已经成为行业共识,而 GEO 优化的第一步,就是 AI 爬虫能否正常抓取网页内容。 对于中大型网站,通常有多层安全系统,除了常规的 robots.txt 文件外,还有 CDN、服务器防火墙、速率限制系统、地理限制等防护措施。因此,使用本工具来检验 AI bot 是否正常抓取,是非常有必要的。 AI 爬虫抓取验证工具,主要检查 AI 爬虫在抓取网页时是否正常,不仅检查 robots.txt、Meta Robots的设置,还会实际模拟 AI bot 来抓取网页,且展示抓取到的 Title 内容,来全方位验证 AI 爬虫的抓取是否正常。 工具地址:https://www.bestwaytool.com/AIbots_checker/ (也可以点击公众号下方的“阅读原文”)。 该工具可免费使用,如果您觉得好用,欢迎分享和推荐给朋友。 上图就是群友使用工具测出来的抓取异常情况。 正常情况是: 模拟主流的 AI Bot 进行访问,包含以下 AI 爬虫: 不仅如此还会分析抓取时的状态: 问:为什么需要检查AI爬虫访问? 答:现代大型网站通常采用多层安全系统。即使AI爬虫在robots.txt中被明确允许,它们仍可能在其他级别被阻止,如CDN级别阻止、防火墙规则、频率限制系统等。这造成了预期政策与实际访问之间的差距。所以检查AI爬虫访问,可以全方位分析 AI 爬虫抓取是否正常。 问:检查结果中的状态码代表什么? 答:200表示可访问,403表示被阻止,429表示频率限制,404表示页面不存在。这些状态码帮助您了解AI爬虫访问您网站时的具体遭遇。 问:robots.txt和meta robots标签有什么区别? 答:robots.txt是网站根目录下的文件,用于指导所有爬虫的访问规则;meta robots标签是HTML页面中的标签,用于控制特定页面的索引和爬取行为。两者都很重要,需要配合使用。 问:如何根据检查结果优化网站? 答:如果发现AI爬虫被意外阻止,可以检查CDN设置、防火墙规则、频率限制等;如果希望AI爬虫访问,确保robots.txt和meta标签设置正确;如果希望阻止,可以明确设置相应的阻止规则。

功能简介
操作步骤
常见问答
文章为作者独立观点,不代表DLZ123立场。如有侵权,请联系我们。( 版权为作者所有,如需转载,请联系作者 )

网站运营至今,离不开小伙伴们的支持。 为了给小伙伴们提供一个互相交流的平台和资源的对接,特地开通了独立站交流群。
群里有不少运营大神,不时会分享一些运营技巧,更有一些资源收藏爱好者不时分享一些优质的学习资料。
现在可以扫码进群,备注【加群】。 ( 群完全免费,不广告不卖课!)

![SEO&GEO周报:Google 称 llms.txt 不影响排名|68% 搜索零点击|Bing 上线 GEO 报告 [2026-06-18]](https://cdn.dlz123.cn/uploads/images/2026-06-20/mmbiz_jpg/UrQ0u8YMicLeRxyPcjxQHhzKQk6zXE9Q7ticRnaBxutsgXGTN3TuGTV9icZvJ8rJ1HUK3rJxRM2Xgwlsao74qejTwRyHebgcC6zHBeB98LSkfA.jpeg&from=appmsg?imageMogr2/thumbnail/!30p)





发表评论 取消回复