https://arxiv.org/pdf/2512.14982
但 Google Research 在 2025 年 12 月发布的一篇颠覆性论文告诉我:其实,你只需要把提示词复制粘贴一遍,效果就能从“不可用”变成“完美”。
是的,这听起来太傻X了。就像以前修电视机靠“拍一下”一样。
以下截图就是 Google Research 专家论文的部分截图,你看他把Prompt直接输入两次,就这么简单。(我当时还以为要等第一轮AI答案输出之后,再复制Prompt,没想到是一次性就输入2个重复的Prompt)

我要用第一人称的视角,带你看看这项被称为 "Prompt Repetition"(提示词重复) 的技术,是如何彻底改变我的 SEO 和市场调研工作流的。
为什么 AI 总是“读不懂”我们的心?
在深入实战之前,我们需要理解 AI 一个根本性的生理缺陷。
Google 的研究员在论文《Prompt Repetition Improves Non-Reasoning LLMs》中指出,目前的主流大模型(如 Gemini,ChatGPT, Claude, DeepSeek)都是“因果模型”。简单来说,它们阅读的方式是单向的,只能从左往右读,绝对不回头。
想象一下,我给你一份 50 页的文档,让你在读的过程中找出“所有提到价格的地方”,但我把这个指令写在了文档的最后一行。 你在读前 49 页的时候,根本不知道要在意“价格”,所以你看得漫不经心。当你读到最后一行指令时,前面的内容你早就忘得差不多了。这就是 AI 经常遇到的**“中间迷失”(Lost in the Middle)**现象。

这正是我们在做 SEO 内容生成和长文档调研时遇到的典型场景:信息在前,指令在后。
科学实锤:重复即正义
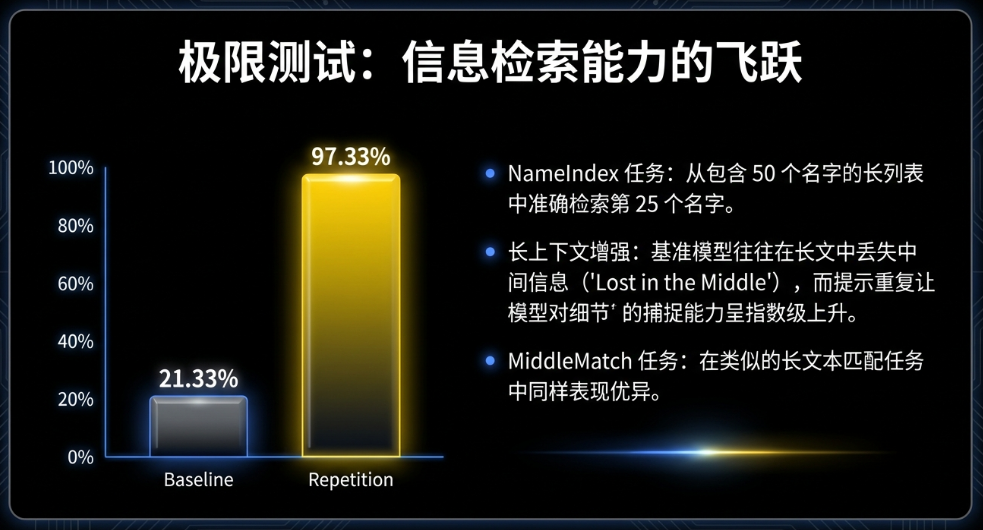
Google 的团队发现了一个令他们自己都震惊的数据。他们设计了一个叫 NameIndex 的测试,本质上就是在一大堆乱七八糟的数据里找特定信息——这和我们做竞品调研简直一模一样。
只说一次: 模型的准确率只有 21.33%。
重复一次(RE2): 模型的准确率飙升到了 97.33%。
仅仅是把输入的内容重复了一遍,准确率提升了 4 倍多。为什么?因为在处理第二遍内容时,模型已经“预习”过了,它带着第一遍末尾的“问题”,重新审视了第二遍的“内容”。这就像给了 AI 一双“透视眼”。

实战应用:如何用“笨办法”做聪明事
读完论文后,我立刻改良了我AI Prompt方法。以下是我亲测有效的两个核心场景:
场景一:深度的竞争对手调研(解决“数据遗漏”)
以前,我把一份 2万字的行业白皮书丢给 AI,问它:“列出文提到的所有公司及其市场份额。” 结果通常是,它只列出了开头和结尾提到的几家大公司,中间的黑马公司全漏了。
现在的做法(RE2 策略): 我不再只发一次。我把 Prompt 设计成这样:
[粘贴 2万字白皮书] [指令:请提取所有公司及市场份额] --- (我是分割线) --- [再次粘贴 2万字白皮书] [再次指令:请提取所有公司及市场份额]
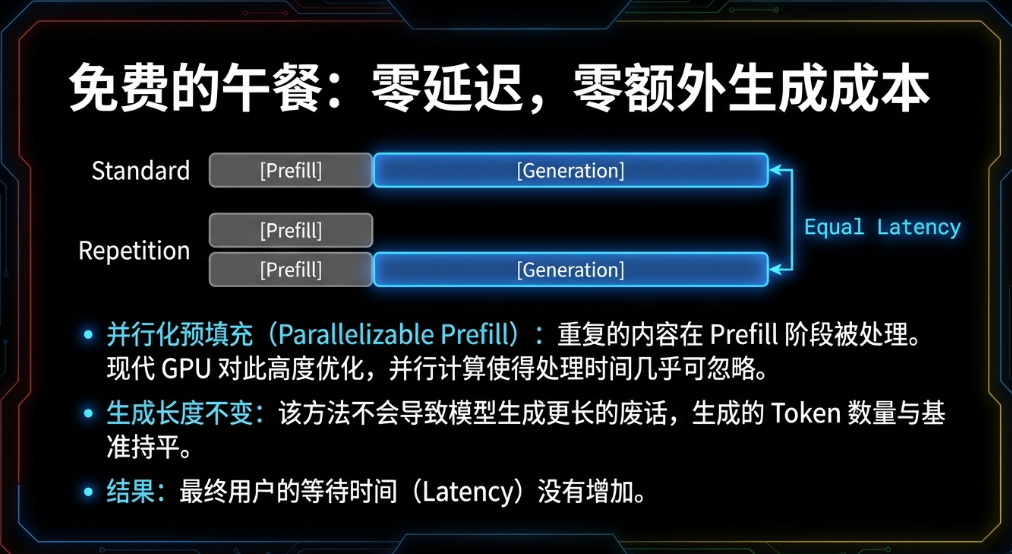
效果: 我发现提取的数据量通常会增加 30%-50%。那些隐藏在报告角落里的数据点,被 AI 一个不落地抓了出来。虽然输入的字数翻倍了,但对于需要精准数据的调研工作来说,这完全值得。
场景二:SEO 文章写作(解决“指令健忘”)
做 SEO 的朋友都知道,我们对文章结构的要求是很死板的:必须包含特定的 LSI 关键词,必须用 H2/H3 标签,甚至要求输出 JSON 格式。AI 经常写着写着就“忘词”了,导致关键词密度不够,或者格式乱套。
现在的做法(三明治重复法): 我不再把 SEO 要求只写在最后,而是采用“三明治”结构:
[第一层 - 核心指令]: 主题:2026年数字营销趋势 核心关键词:AI代理、零点击搜索、视频SEO 格式要求:严格遵循 H2-H3 结构,关键词自然植入。
[第二层 - 参考素材]: (这里粘贴你的背景资料、参考文章...)
[第三层 - 重复指令]: 重要提示:请再次确认你的任务: 主题:2026年数字营销趋势 核心关键词:AI代理、零点击搜索、视频SEO 格式要求:严格遵循 H2-H3 结构,关键词自然植入。
效果: 这种重复就像是在对 AI 耳提面命。我发现生成的文章中,关键词的覆盖率几乎达到了 100%,而且它们出现的位置更自然,不再是生硬地堆砌在结尾。对于要求输出 JSON Schema 的技术性 SEO 任务,这种方法的格式错误率几乎为零。
当然这个方法用在纯血版SEO小语种的场景也是YYDS的。

大家关心的成本问题:会变贵吗?
很多朋友可能会问:“输入内容翻倍,我的 API 费用岂不是也要翻倍?”
确实,输入 Token 变多了。但是,我们需要算一笔账:
输入比输出便宜: 在 DeepSeek 或 GPT-4o-mini 等模型中,输入 Token 的价格极低(通常只有输出价格的 1/10 甚至更低)。
缓存红利(Prompt Caching): 现在主流模型(DeepSeek, Claude, Gemini)都支持“提示词缓存”。如果你重复发送相同的大段背景资料(Prefix),第二次的成本几乎可以忽略不计。
避免返工: 以前我因为 AI 漏数据,需要人工复核半小时,或者重新生成三次。现在一次搞定。在这个“人工比算力贵”的时代,多花几分钱的 Token 费来节省半小时的人力,简直是暴利。
我们正处于一个有趣的 AI 阶段。一方面,模型越来越聪明;另一方面,它们依然有着像“只能从左往右读”这样原始的局限。
Google 的这篇论文提醒我们,有时候最有效的解决方案不是寻找更高级的模型,而是回归最朴素的逻辑:重要的事情说两遍。
如果你的 AI 在做数据提取、格式转换或遵循复杂 SEO 规则时表现不稳定,别急着怀疑模型,试试 Ctrl+C,Ctrl+V。这可能就是你离“完美结果”之间,那层还没捅破的窗户纸。
我是持续输出谷歌SEO干货的SEO小平,欢迎关注和点赞。

文章为作者独立观点,不代表DLZ123立场。如有侵权,请联系我们。( 版权为作者所有,如需转载,请联系作者 )

网站运营至今,离不开小伙伴们的支持。 为了给小伙伴们提供一个互相交流的平台和资源的对接,特地开通了独立站交流群。
群里有不少运营大神,不时会分享一些运营技巧,更有一些资源收藏爱好者不时分享一些优质的学习资料。
现在可以扫码进群,备注【加群】。 ( 群完全免费,不广告不卖课!)







发表评论 取消回复