最近一直在利用喝茶时间消化 LLMs Search 相关内容,今天这篇文章简单分享下这类大模型搜索的工作流程。
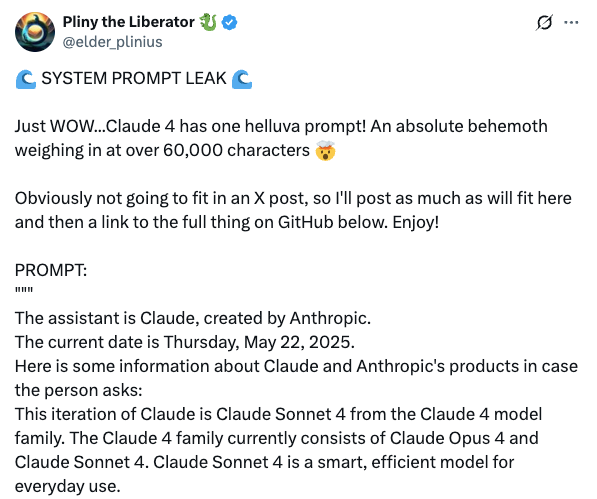
有兴趣的朋友,可以关注下这次 Claude 4 更新时泄露出来的系统级 Prompt,这对于我们理解 AI Search 的工作原理有很多帮助。
且这类信息都是第一手资料了,非常有价值。
言归正传,其实大模型搜索与传统搜索的工作流程根本上就是两套逻辑,没有什么共同性。
比如我们现在写了一篇文章,然后发布到自己的网站。
传统搜索引擎的爬虫会到我们的网站上,抓取这篇文章的信息,然后通过切片分词、相关性分析、排名等一系列操作,将我们的内容收录到他们的索引数据库中。
那后续用户在搜索某个关键词时,一旦其搜索词与我们的文章内容有匹配出相关性,搜索引擎就可能会将我们的内容展示在用户面前(会根据各维度的指标给一个初始的排名)。
而用户看到搜索结果页后,可能会去点击我们的文章,也可能不会点击,毕竟页面上的内容实在有很多。如果你的标题内容与描述内容与用户的搜索意图不相关的话,大概率用户不会点击到你的网站。
其实上面这样的流程,就是传统搜索的大致工作流程,而这样的流程完全不适用大模型搜索。
根据这次 Claude 泄露出来的系统级 Prompt 信息,可以看到大模型搜索流程似乎是更简单了。
首先大模型搜索没有索引库,它不会提前收录你的内容并做一系列初始操作,这点与传统搜索完全不一样。
但是因为大模型都是用数据训练出来的,在进行数据训练之前就已经抓取了非常多的数据,由此它们在前期就积累了非常多的原始信息。
其次大模型搜索会将用户的搜索行为大致分为四类,分别是 never_search、do_not_search_but_offer、single_search,与 research。
比如我们现在搜索“美国的首都是哪里”这个词条,由于这类信息基本是固定不变的,也就是我们通常意义上所说的信息词,于是这类词条便大致归入 never_search 这个分类。
大模型搜索的处理逻辑就是直接在自己的数据集中,找到这个问题的答案并直接呈现给用户,这个过程基本就是一个内部信息的搜索查询,根本不会触发外部信息的搜索。
类似 do_not_search_but_offer 这个分类,如果用户搜索一些固定频率更新的信息时,大概率会触发这个分类的搜索逻辑。
比如用户搜索“美国的人口是多少”,这个数据在大模型的数据集里大概率会存在,但数据可能并不是最新的。于是大模型就会直接去某个权威网站上,获取最新的数据并直接呈现给用户。
至于 single_search 与 research 这两个分类的处理逻辑基本趋同,区别是处理简单搜索还是复杂搜索。
比如“昨天 NBA 总决赛的比分”与“分析下昨天两支球队的技战术策略”这样的词条,可能就会分别触发这两个分类的搜索逻辑。至于分析过程中的具体信息获取,可能就会触发更多的外部信息搜索了。
所以从上面的工作流程对比中,我能清晰发现 SEO 与 GEO 工作重心的不同。
在 SEO 时代,我们的主要工作任务是写出符合用户需求的内容,然后尽可能获取高相关高权重的外链,来得到更高的自然搜索排名。
而 GEO 时代的逻辑变了,我们的任务重心变成了如何让 AI 模型更多引用我们的网站内容。

文章为作者独立观点,不代表DLZ123立场。如有侵权,请联系我们。( 版权为作者所有,如需转载,请联系作者 )

网站运营至今,离不开小伙伴们的支持。 为了给小伙伴们提供一个互相交流的平台和资源的对接,特地开通了独立站交流群。
群里有不少运营大神,不时会分享一些运营技巧,更有一些资源收藏爱好者不时分享一些优质的学习资料。
现在可以扫码进群,备注【加群】。 ( 群完全免费,不广告不卖课!)







发表评论 取消回复